User feedback driven LLM development
“Write code. Talk to users.”. That’s the advice Y Combinator gives its founders at the start of every batch. And I think it really underlines that how your users feel is really the only true north metric that matters. Any evaluation models that measure different components of your output, are ultimately trying to approximate ‘will my user like this?’.
With that in mind, actually asking your users how they feel about an output is an incredibly useful way to get a goldmine of data. What sessions do your users like a lot? Is there anything about them you can amplify or make more consistent? What about sessions your users weren’t happy with? What’s causing those bad ratings? Is there a known error you didn’t catch? Or have your users found a new kind of ‘break’ or error that you need to track now?
 ChatGPT's UI for user feedback.
ChatGPT's UI for user feedback.
We’ll go over how to add a ‘User Feedback’ feedback loop to your LLM development. Let your users rate your sessions in product, collect the data in your observability platform, and use it in your evaluations and analytics.
Adding feedback to your UI
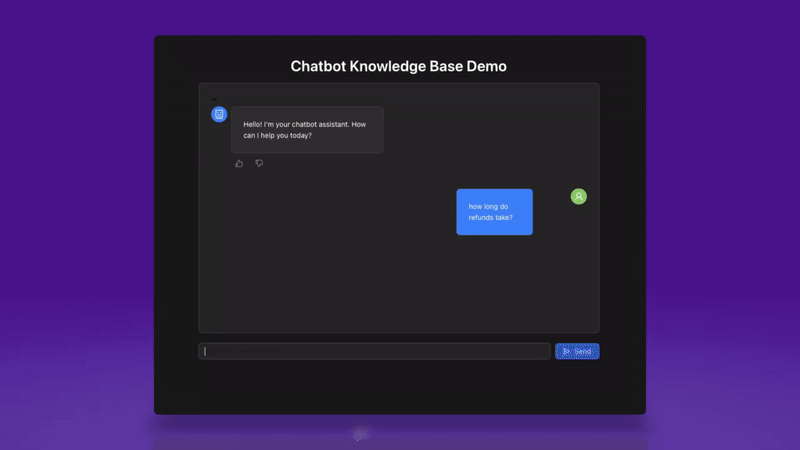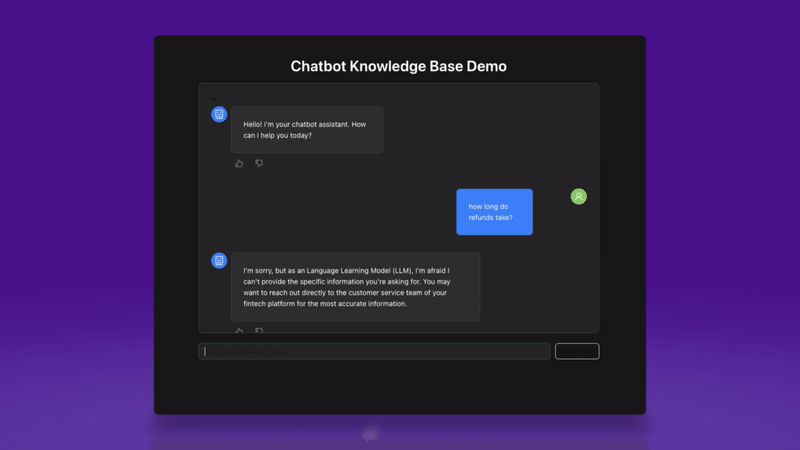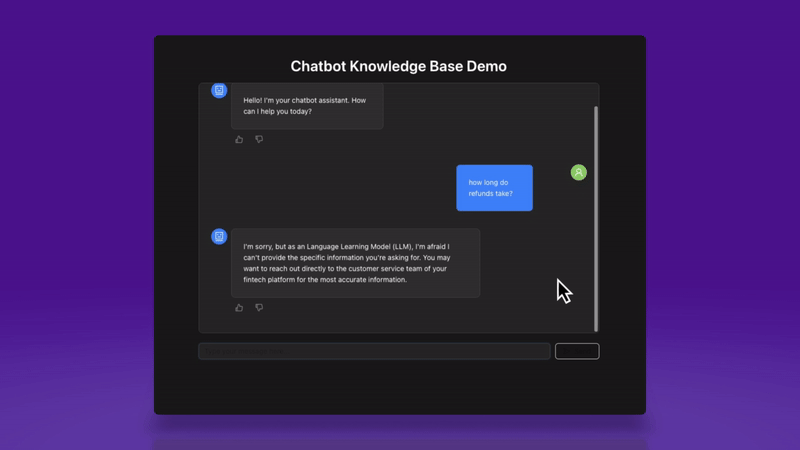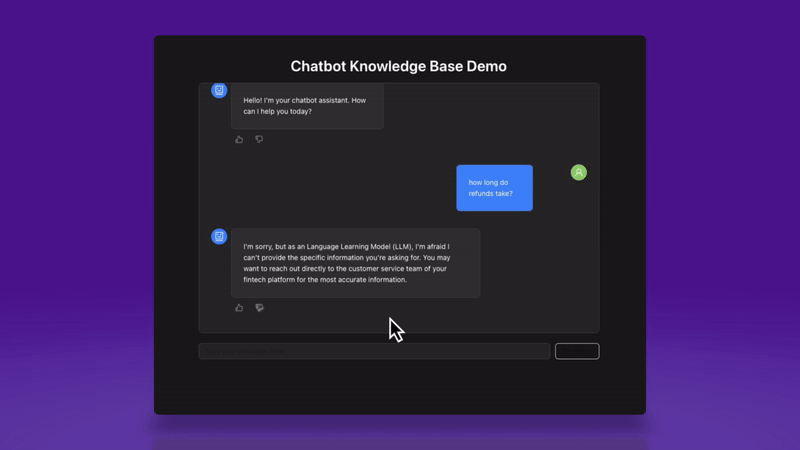
First, we’ll add some space for users to rate the response by adding basic thumbs up/thumbs down icons below the output generation (similar to ChatGPT’s flow).
Here’s how that will look for a positive response.
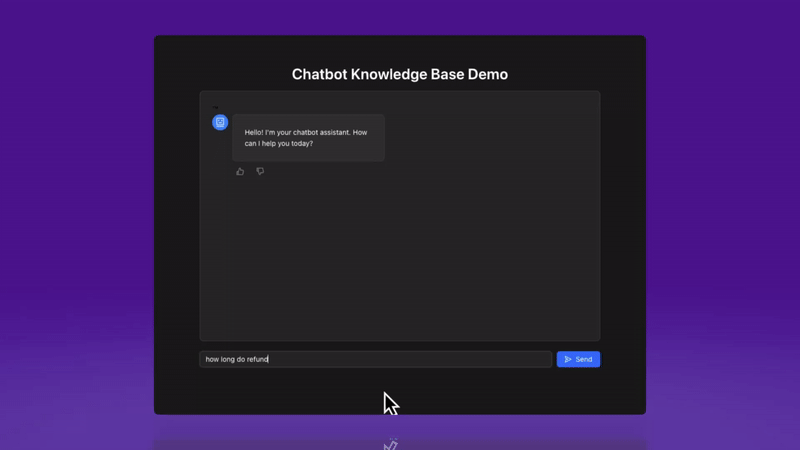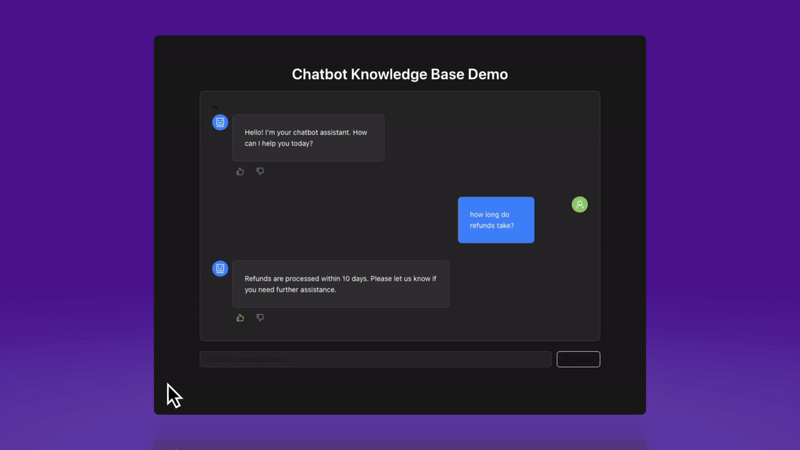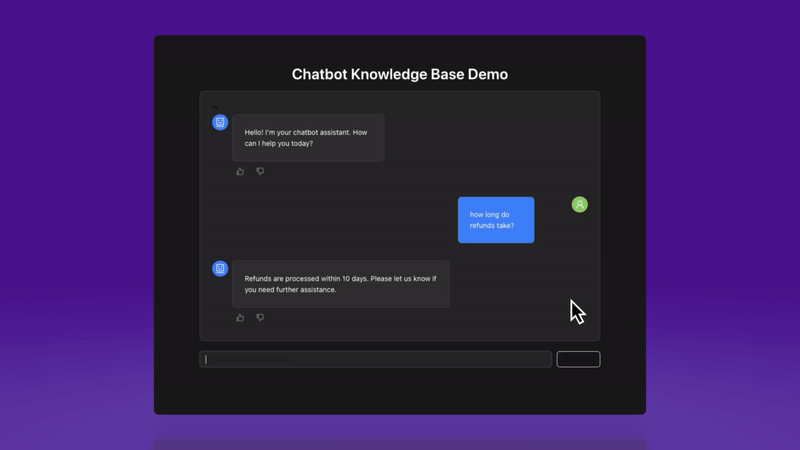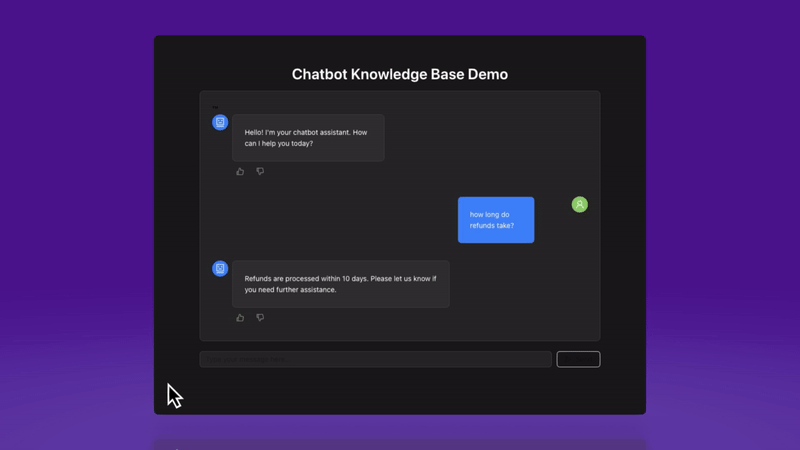
And here’s how it looks for a negative response.
Tracking feedback
Under the hood, we’ll use the lytix User Feedback (opens in a new tab) logger, to save the feedback in our dashboard (obviously - we’ll hook the ‘positive feedback’ call to the thumbs up icon, and the ‘negative feedback’ call to the thumbs down icon). Check out our docs for more context on how these are set up.
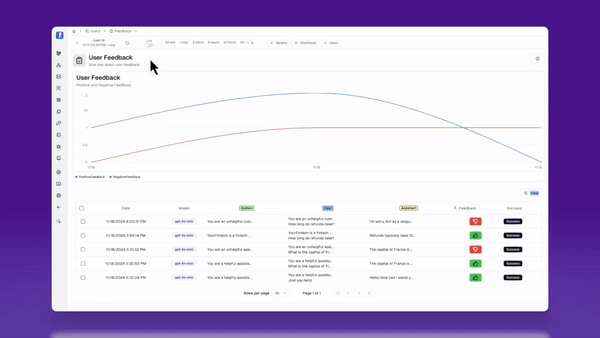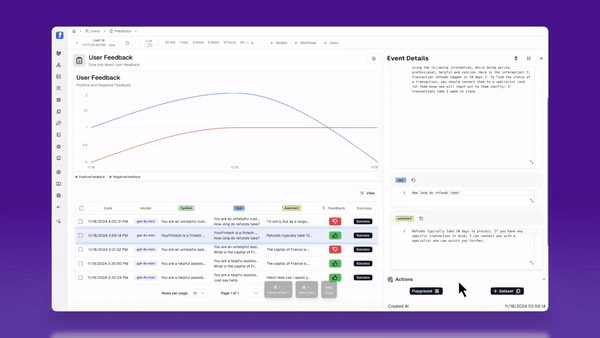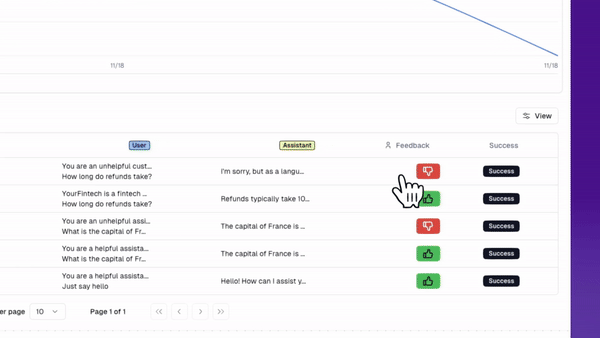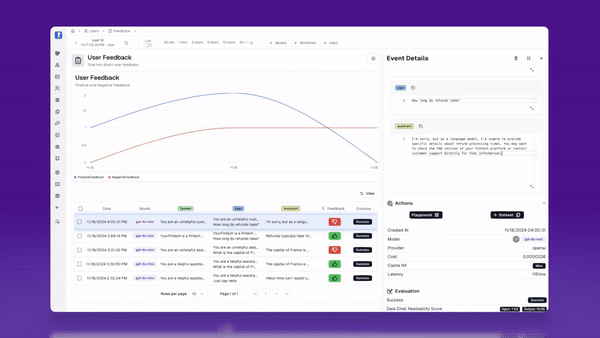
Now, we should be able to find out user feedback in our dashboard, and dive deeper into each session to learn more.
Under “Users” in the sidebar and “Feedback”, we can now see each session, along with how the user rated it.
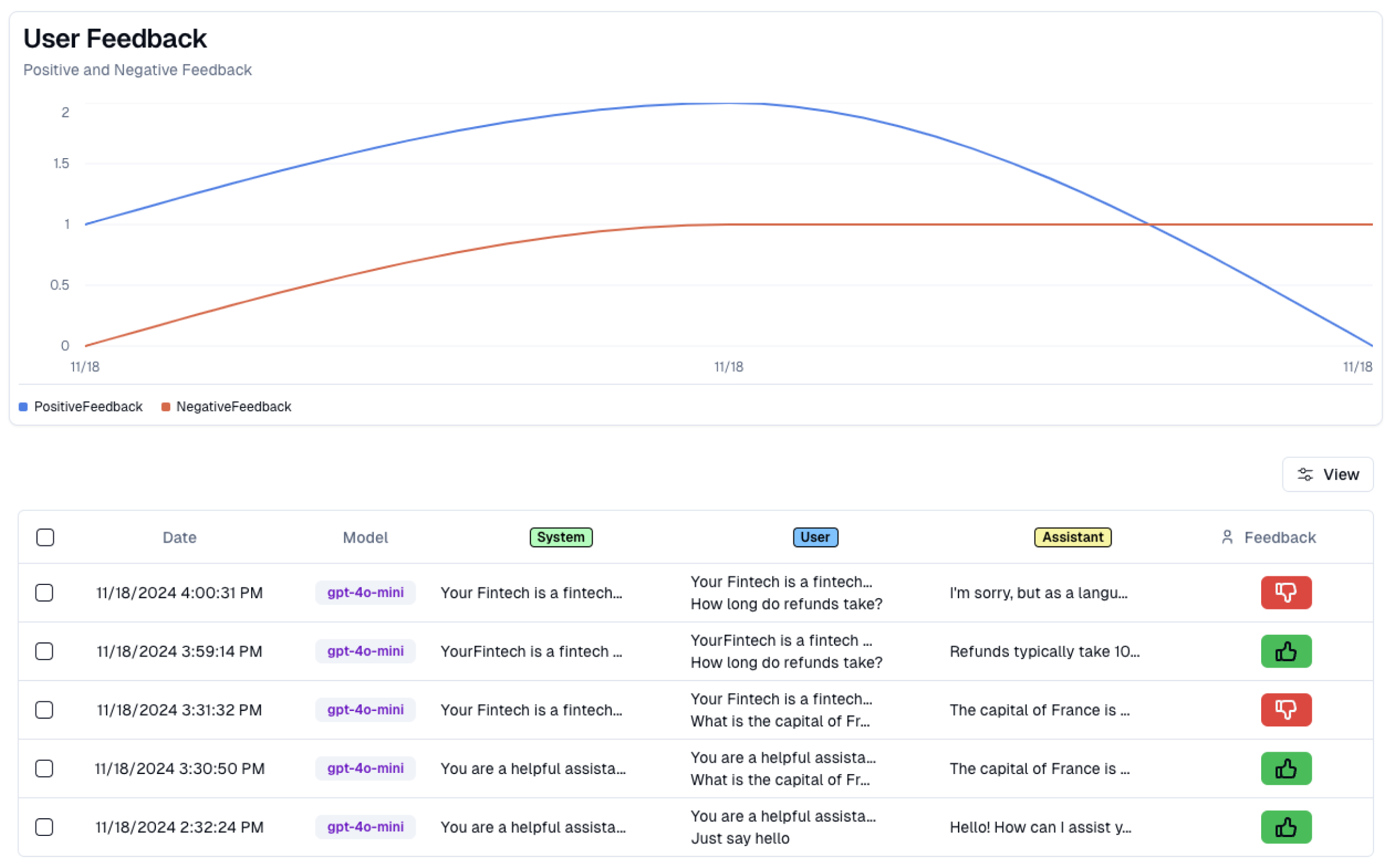
I can dive deeper into each session to learn more, and figure out what actions I can take next.
Using your data
- Edit your prompts to reduce instances of negatively rated qualities, or increase instances of positively rated qualities
- Build evaluators for commonalities across ‘negatively rated’ sessions. This will let you track instances of ‘negative’ qualities, without relying on your users manually reporting them. You can start with a custom evaluation (opens in a new tab), using the negative examples as examples.
- If you have enough data, you can even finetune your own SLM evaluator agent (opens in a new tab).
- On that note - you can also start finetuning your own language models using ‘positively’ rated sessions. This is almost like building a model using ‘human in the loop’ feedback, except your users are your feedback agents!
Happy building!
🚀 This post was a deep dive into a recent launch at Lytix 📣 If you are building with AI/LLMs, please check out our project lytix (opens in a new tab). It's a observability + evaluation platform for all the things that happen in your LLM.
📖 If you like content designed for people building with LLMs, sign up for our newsletter! You can check out our other posts here(opens in a new tab) (opens in a new tab).
© lytix