A practical guide to building custom evaluations
Evaluations are models (or more likely, systems of models (opens in a new tab)) that monitor and measure the performance of your LLM systems. While evaluations have been around in the MLOps worlds for years, LLM developers face a new set of challenges when it comes to evaluating their systems in production.

They're critical for maintaining any reliable LLM-driven systems in production. Many developers quickly recognize the need for evaluations, as soon as they start building systems powered by LLMs. But in spite of how obviously important they are, we see the majority of developers bogged down by the ambiguity and complexity of building evaluation sysems.
1. Subjectivity
Now that models are producing writing, images and video - it’s gotten harder to objectively evaluate outputs as ‘good’ or ‘bad’. For example - how can you, at scale, measure to what extent your agent is communicating as per your ‘brands’ tone? What about qualities like ‘conciseness’? Where the answer could be different for different user groups.
2. Domain specific knowledge and reasoning.
In many use cases, one of the most important aspects to evaluate is if the information in the output is correct. Especially where agents are being deployed to communicate specific knowledge bases, or where the stakes of getting things wrong is high. Ideally, you’d have a human domain-expert evaluating every output. But how can you build a scalable system like that?
3. “Vibes” - do I know what I’m looking for?
What about when you know what good and bad looks like - but you’re struggling to effectively articulate what they look like? Let alone build systems that can effectively catch each? That’s the situation we see a lot of developers in. Able to look through a set of logs and manually identify the good or bad, but would struggle to articulate the precise qualities they were looking for.
Here’s how you can use Lytix’ Custom Evaluations, to build evaluations around these challenges. This guide will go over:
- Build a net-new custom evaluation, using natural language and example events
- Setting up a family of evaluators, evaluating different qualities of my output
- Tracking them live, identifying edge-cases or noteworthy sessions
- Creating eval-driven feedback loops
We’ll use this example ‘text to sql’ app, that lets users interact with a database using natural language. Assume it’s made of 3 agents: one that turns the users question into a SQL query, a second that runs the SQL and produces a table, and a third that summarizes the results.
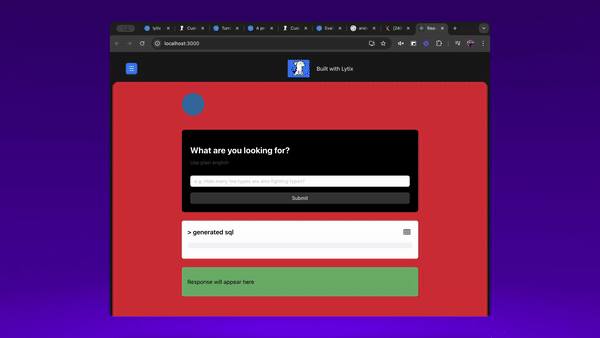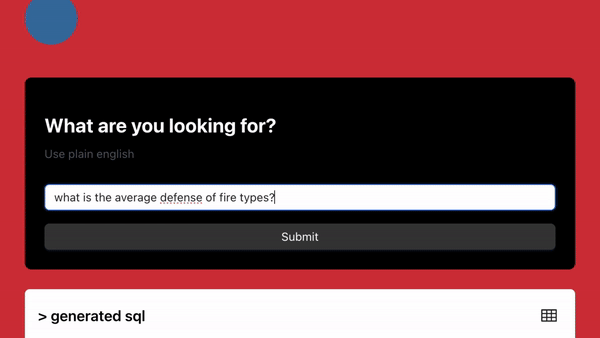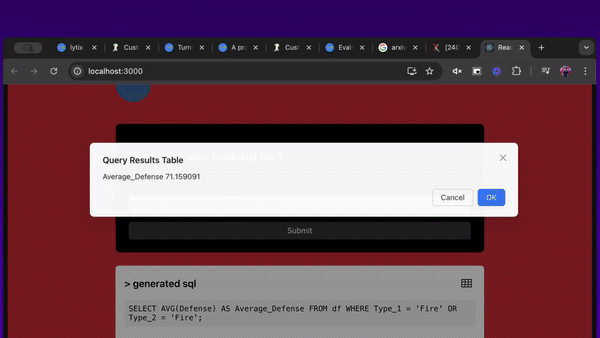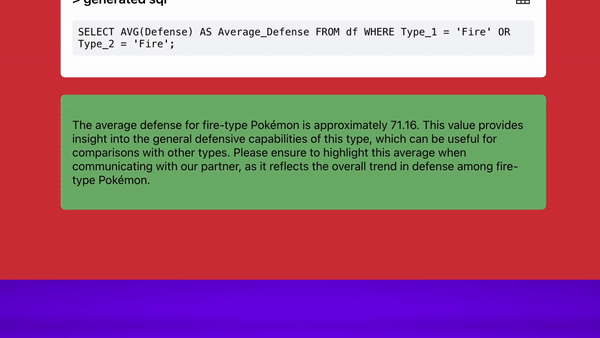 Example app that lets users interact with a database using natural language. An LLM turns the users question into a SQL query, which is run against a database and the results are summarized.
Example app that lets users interact with a database using natural language. An LLM turns the users question into a SQL query, which is run against a database and the results are summarized.
Build a net-new custom evaluation, using natural language and example events
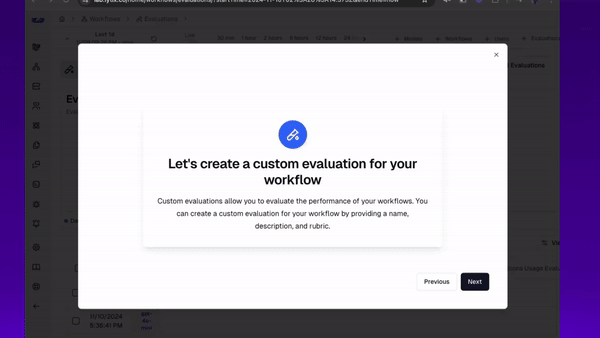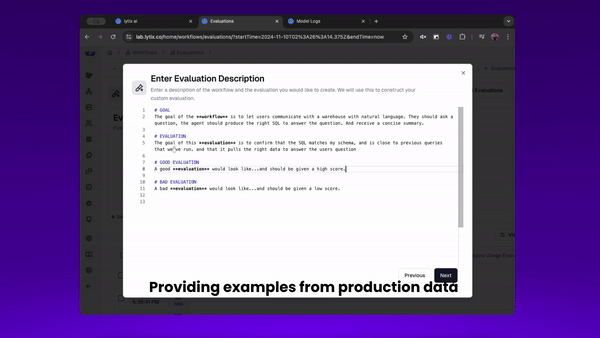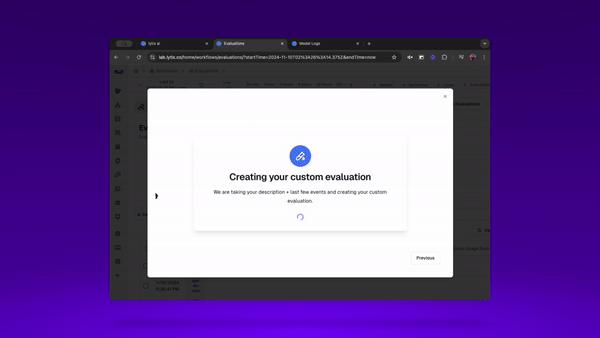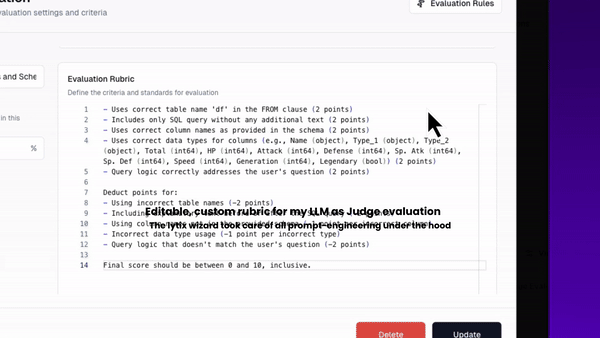
First, we’ll go over how to build a new custom evaluation. Lets say we want to evaluate if the SQL being generated is valid - that it matches my databases specific schema? And it queries the right data in order to answer the users question.
Here’s how I can build a custom evaluator with the right domain knowledge, to monitor this overtime.
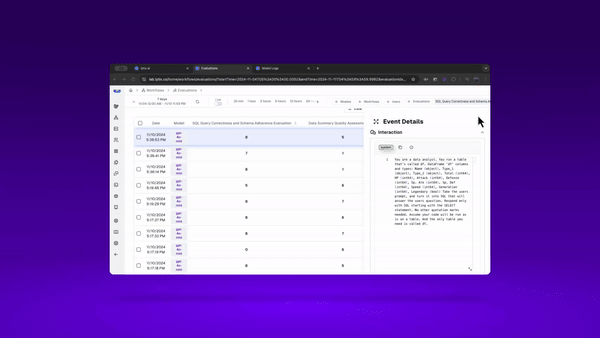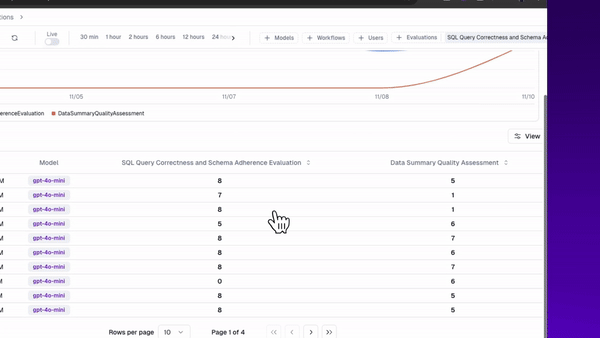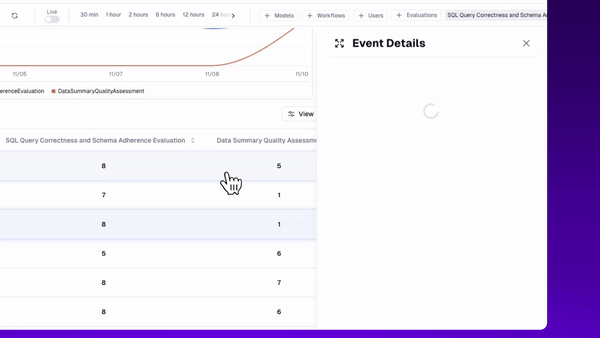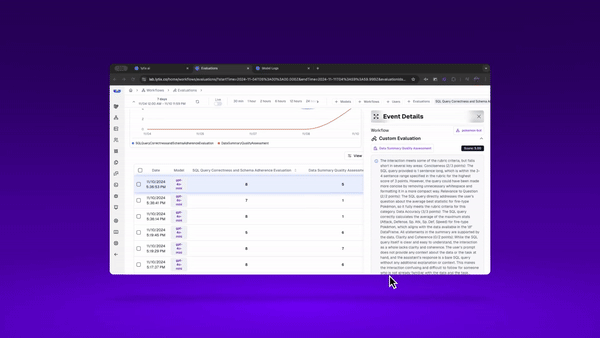
And here’s how I can track that over time, and find sessions where my agents are creating errors or performing lower than I’d expect.
(Check out this paper on the strength of prompt-optimized LLM as Judge models for evaluations. If you’re not using a wizard like lytix - remember to continuously iterate on the prompt-engineering under the hood.)
Tracking multiple evals live - finding edge cases + noteworthy sessions
Next, lets say that I’d like to evaluate a secondary aspect of my system - if my agent is communicating the results effectively and accurately.
I could try and have one agent evaluate both the sql and the chatbot. But that feels a little unnatural since they’re both different agents. In cases like this, it’s best to set up an additional custom evaluator agent, evaluating specifically the agents communication.
Here’s how that my dashboard looks now with my 2 evaluator agents
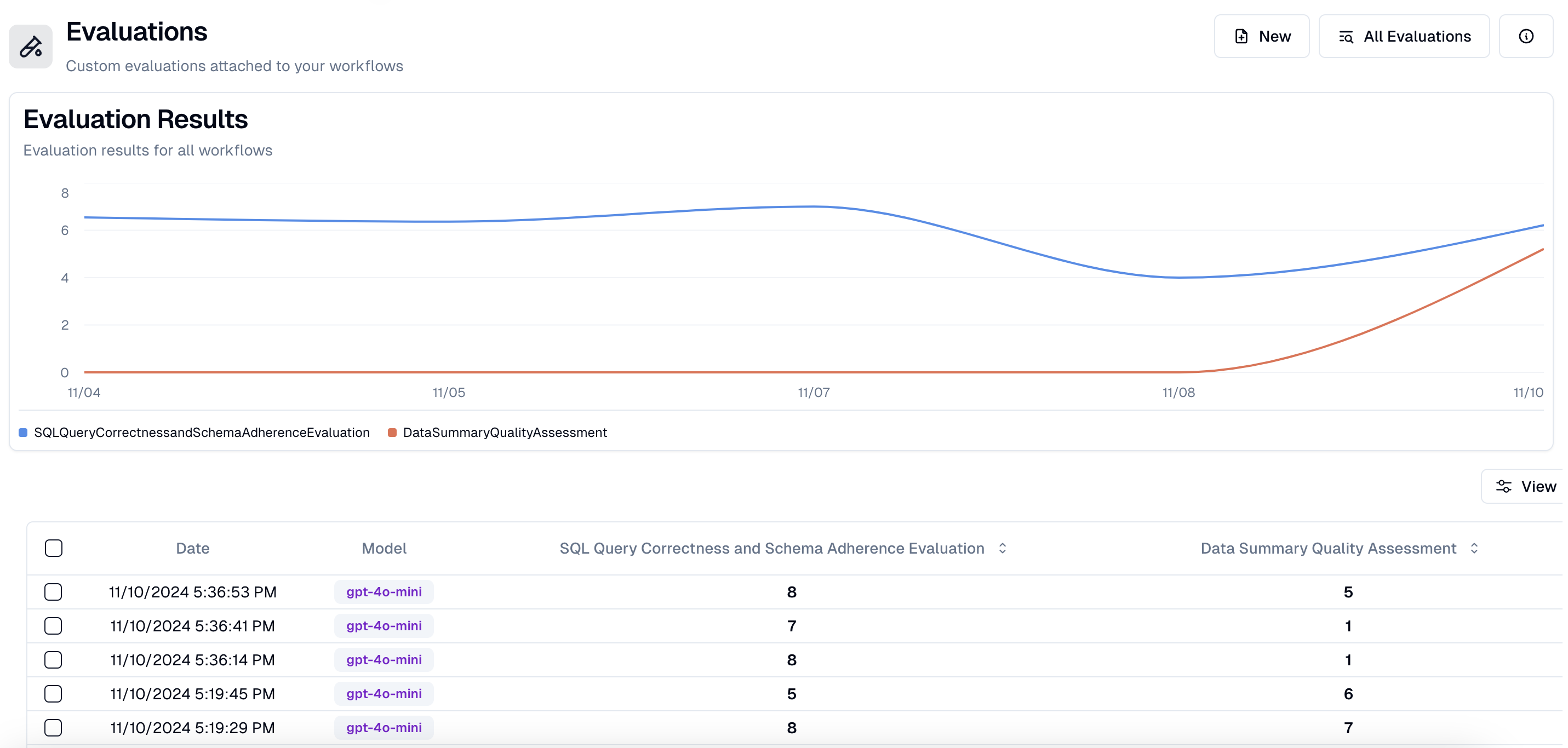
(If you’re nervous about the effectiveness of multiple models - here’s a paper on the benefits of a ‘family of judges’ approach)
Now that I have these in place, here’s how I can use them to stay on top of my system.
I can use my dashboard and the logs to identify failures and sessions of ‘lower’ performance.
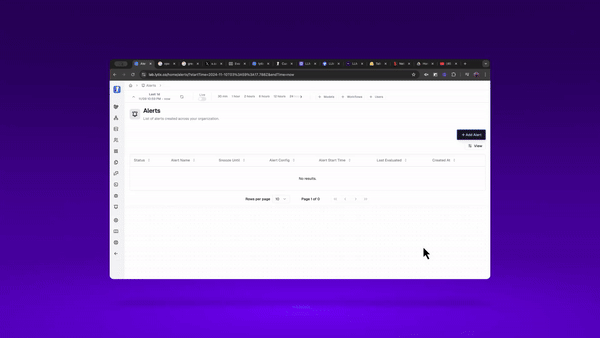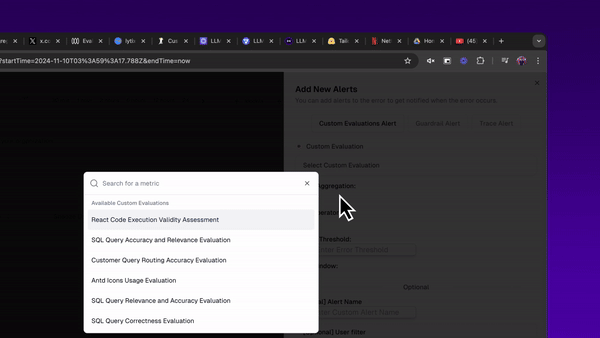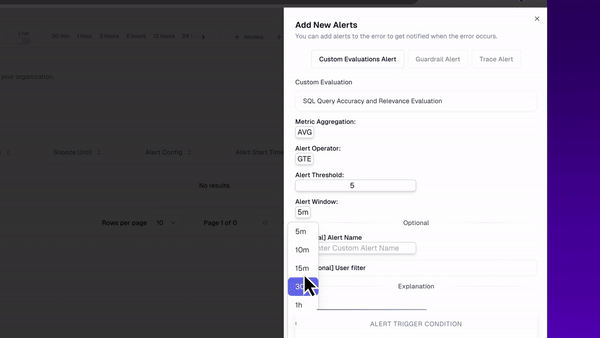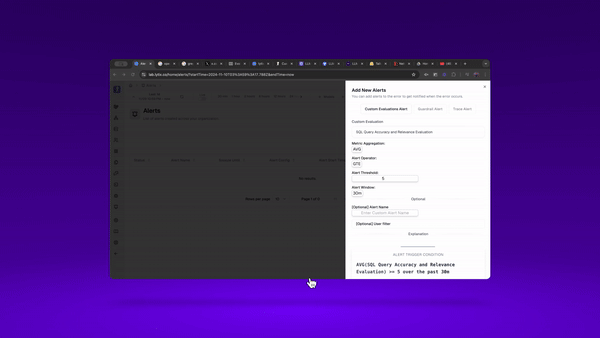
I can also set up an alert for anytime my evaluators dip below some ‘failure’ threshold. This way, anytime my system dips below a certain performance threshold, I’ll get an alert.
Creating eval-driven feedback loops
Finally, I may want to keep track of events that are particularly ‘good’ or ‘bad’.
Good events could be helpful for finetuning my own models, creating models that more reliably produce the kinds of outputs I’ve saved as exemplars.
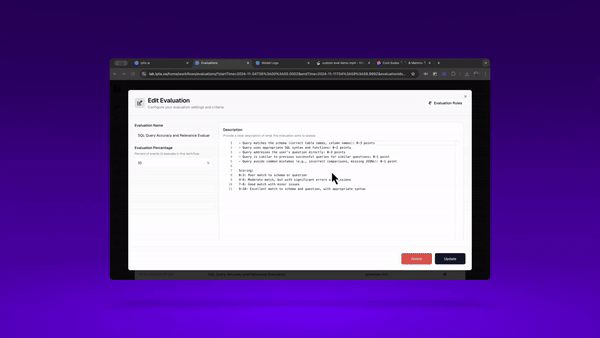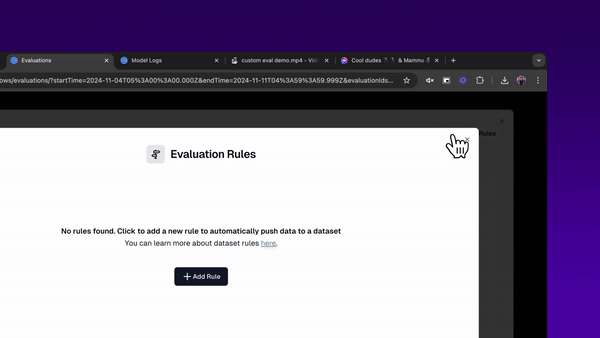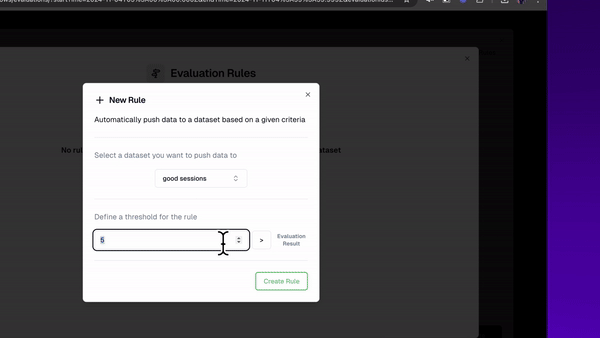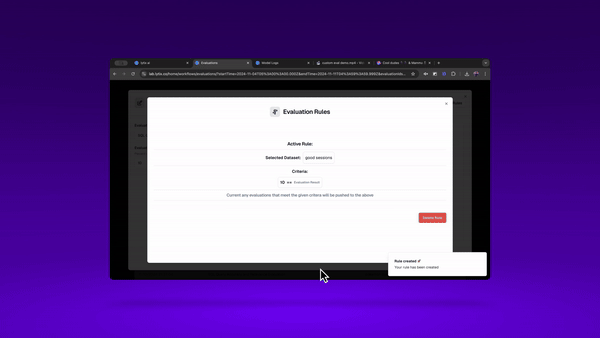
I can repeat this process for ‘bad’ events. This could be helpful for finetuning your own eval models. Turning your k-shot, LLM as Judge prompts, into their own small language models. These can be faster, cheaper and more reliable than prompt-engineered large language models. (Here’s (opens in a new tab) an example guide of building a finetuned eval model, using a static dataset. You can use this logic for building evaluations from any static datasetof example model inputs/outputs)
Check out the docs 📃 (opens in a new tab) for how to get started with custom evaluations
© lytix