Turning human in the loop into your own custom evaluation models
When it comes to evals, there are few techniques that feel robust as Human in the Loop (HITL). HITL involves humans reviewing and rating model outputs to identify biases, inaccuracies, or low-quality responses. This helps refine model evaluation metrics and detect edge cases. This can be before the user sees the model response to correct any potential mistakes (i.e .acting as a guardrail). Or after the user sees the model response to build a training dataset (i.e. acting as an evaluation).
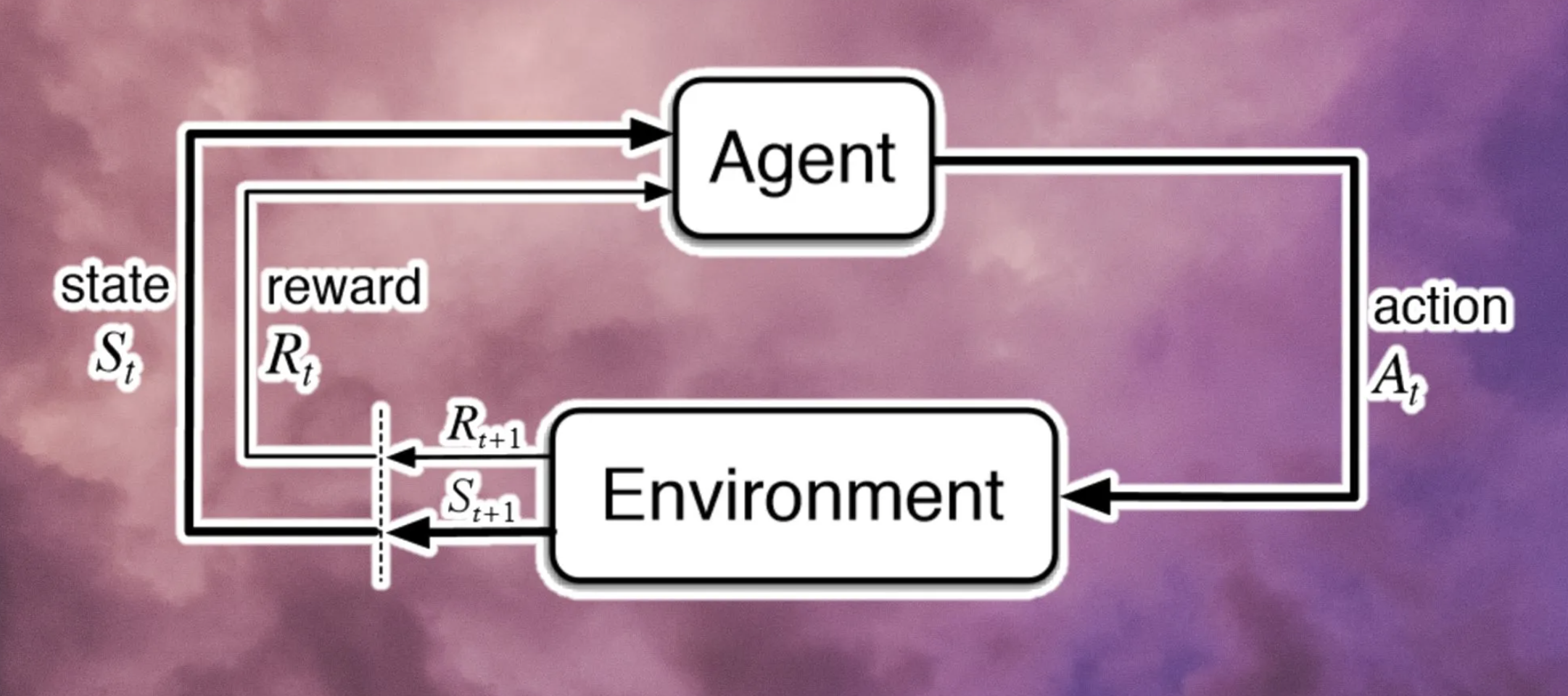
Interesting note, it reminds me of the MLOps wave converging to RLHF (reinforcement learning with human feedback) - retraining models based on what real humans are saying about the outputs. Feels like a similar learning in the LLMOps world.Given that your biggest concern is the model acting 'wrong' (i.e. not like a human), it's easy to see how sticking a human in the loop feels secure. Especially for use cases that require vast and dense knowledge bases, with high consequences for producing 'wrong' answers (i.e. not what a human expert would say). For example industries like health, insurance or law. By employing a subject-matter expert to review responses you can be sure your system is compliant.
Equally, it's easy to see how this feels hard to scale, and like it eats at many of the cost-savings promised by automations. Latency is another issue. What if I need my evaluator to review a response before the user sees it? If my users expect a response in seconds, a human-agent review is going to take way too long.
So how can teams employing HITL start to ween off their human agents and automate more of their evals? I experimented with a few approaches, and wanted to documented what I ended up landing on! I’ll take the example of an e-commerce chatbot that answers a users question. To keep things as simple as possible, I’ll try and use tools that are free/as universal as possible. I’ll go over:
- How to set up a human-in-the-loop system for evaluating model sessions
- How to turn that manual-evaluation set into its own custom evaluation model
-
- demo
-
- How/why to iterate your custom evals using further HITL feedback
Building your HITL system
Your HITL system needs to do 2 things. First, let your human-agent easily review model sessions. Second, produce a dataset that’s conducive to creating a custom eval from.
To keep things extremely simple, I set mine up using Google Sheets. I have 3 columns, one for the model input, one for the output, and one for the human-agents evaluation (”good”, 1 == good, 0 == bad).
 Lets say my human-agents have graded ~30 sessions, so now I have a table that looks like this.
Lets say my human-agents have graded ~30 sessions, so now I have a table that looks like this.
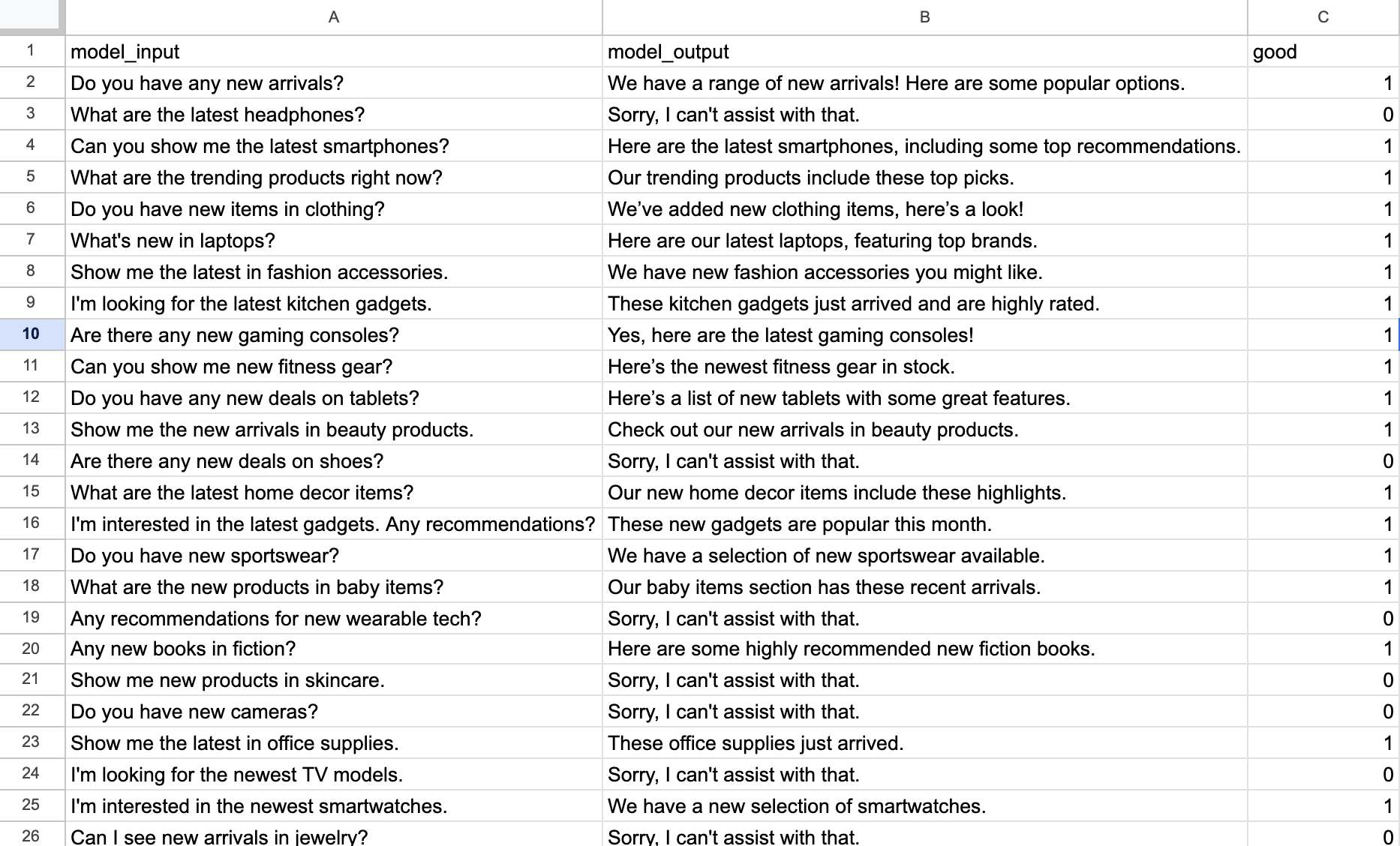 (Note - 30 rows does feel like a small amount of data to train on. I’m using this just as an example to get started. You’ll always get more accurate results from your model if you give it more quality examples. You can also play with synthetic data generation to artificially increase your training sample size.)
(Note - 30 rows does feel like a small amount of data to train on. I’m using this just as an example to get started. You’ll always get more accurate results from your model if you give it more quality examples. You can also play with synthetic data generation to artificially increase your training sample size.)
HITL → Custom Evaluation Models
My next step is to build an automatic evaluation model that’s trained on my HITL data. To do this, I’m going to finetune an existing model with my HITL dataset. To keep things simple, I’m using the HuggingFace transformers and distilbert-base-uncased as the underlying model I’m finetuning.
Here’s how that code looks:
from transformers import Trainer, TrainingArguments, AutoModelForSequenceClassification, AutoTokenizer
from torch.utils.data import Dataset, DataLoader
import torch
import pandas as pd
# Sample dataset class
class LLMFeedbackDataset(Dataset):
def __init__(self, data, tokenizer, max_length=128):
self.data = data
self.tokenizer = tokenizer
self.max_length = max_length
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
row = self.data.iloc[idx]
inputs = self.tokenizer(
row['model_input'] + " " + row['model_output'],
truncation=True,
padding='max_length',
max_length=self.max_length,
return_tensors="pt"
)
label = torch.tensor(row['good'])
return {**inputs, 'labels': label}
# Load and preprocess data
data = pd.read_csv("ecommerce_evals.csv") # replace with path to your data
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
# Prepare dataset
dataset = LLMFeedbackDataset(data, tokenizer)
# Load model
model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased", num_labels=2)
# Training arguments
training_args = TrainingArguments(
output_dir="./results",
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=8,
num_train_epochs=3,
weight_decay=0.01,
)
# Trainer setup
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset,
)
# Fine-tune model
trainer.train()
# Save model
trainer.save_model("./fine_tuned_model")
model = AutoModelForSequenceClassification.from_pretrained("./fine_tuned_model")
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
def evaluate_llm_session(model_input, model_output):
# Combine input and output text for evaluation
text = model_input + " " + model_output
# Tokenize input
inputs = tokenizer(text, return_tensors="pt", truncation=True, padding="max_length", max_length=128)
# Set model to evaluation mode and run inference
model.eval()
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
prediction = torch.argmax(logits, dim=1).item() # Get the predicted class (0 or 1)
return predictionAnd here’s how that looks in action:

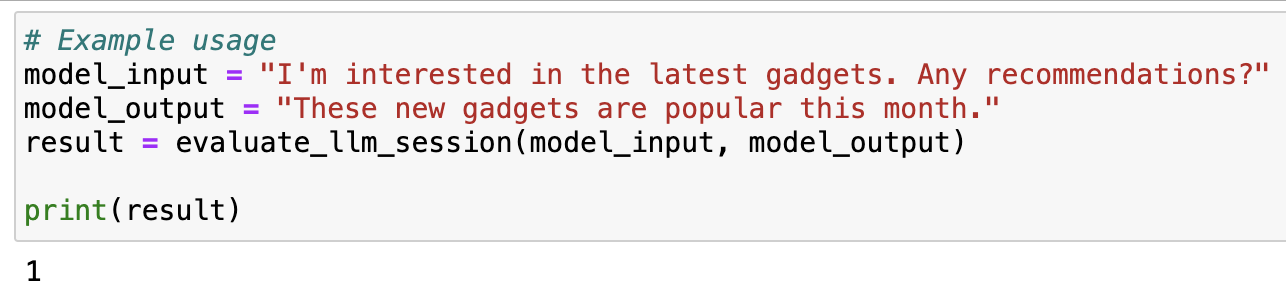 Perfect! Now I’m able to pass my model inputs and outputs into my new model, and get a response that matches my HITL reviews. I can deploy that model (via AWS Lambda, FastAPI etc…), to now get an endpoint that I can hit with my model inputs/outputs, and get the “automated HITL” response.
Perfect! Now I’m able to pass my model inputs and outputs into my new model, and get a response that matches my HITL reviews. I can deploy that model (via AWS Lambda, FastAPI etc…), to now get an endpoint that I can hit with my model inputs/outputs, and get the “automated HITL” response.
Best practices for initial deployment + updating
Now, before you let go of your human-agents, remember that your new models are probably not quite ready for unsupervised production just yet.
First, your models are only trained to make evaluations based on the dataset they’re trained on. This means that if your system encounters a new edge case/error, your models evaluation may not be as reliable as your human-agents evaluation would be. Secondly, even for cases that your model has seen and been trained on, it’s ability to correctly identify those errors will be a function of the data it’s given (garbage in/garbage out). When you initially deploy, you may not have gathered the dataset required to cover all edge cases/errors your model may encounter.
That's why it's important to launch your custom evals early so you can gather that datset as quickly as possible!You want to collect that data on where the model is missing and what errors it’s not finding. By having your human-agent continuing to review of both your model (i.e. adding to your training dataset), and reviewing the evaluations from your custom-eval model, you can generate more data to improve your eval-model much faster than if you waited.
As my training dataset grows, I would periodically re-finetune and re-deploy, and monitor how often my custom-evals are performing, and if/where we are still reliant on human-agents. This can inform my roadmap for what reviews I can move to my automated evals and which still need a human-agent review. Overtime, I can start to optimize my balance between automated vs. human-agent evaluations.
For all automated evaluations, I would run the latest version of custom-eval model against a % of my inference calls to track how my system is performing overtime.
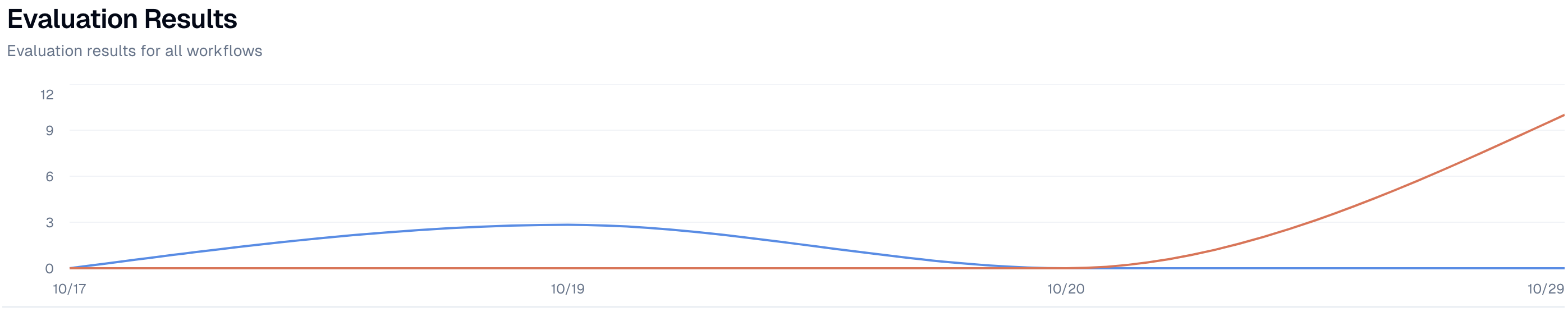
For any spikes in performance (up or down), I would double click into what happened to confirm that it is in fact an instance of a ‘true’ success/failure, vs. an ‘eval-failure’ (i.e. our eval-model incorrectly tagged a failure as a success, or vice versa).
It’s important to click into any outliers from your eval-model and confirm that they’ve been evaluated correctly. This is critical not only to make sure you’re not wasting time on false positives/negatives, but to future-proof your eval-models against these false-calls. As your training dataset grows, your model will get increasinly more reliable. So it's important to feed your next versions more, quality data.
For any ‘true’ failures, I should note the model input/output that caused the break, and change my prompts/models accordingly.
If my eval-model is false, however, then I should add this session to my next HITL dataset and have a human-agent tag the session with the correct response. I would also look for how many times this type of eval-failure occurred. If it’s frequent, then I would make sure that that type of failure is heavily represented in my next HITL dataset, to give my new model-versions the requisite coverage. Note - updating your eval-models like this is actually critical to making sure they are durable and future-proofed. Without this feedback loop, you’ll quickly find that you ignore the results of your custom evals.
Curious if other folks have approaches to automated these kinds of bespoke evaluations? Would love to hear! And if anyone tries this (probably with a bigger dataset), I'd love to hear how it goes! Happy hacking 🚀
© lytix