How evaluations will fit into your future LLMOps stack
This guide is designed for teams excited about the potential for LLMs, but looking for some guidance for how to instrument systems that are reliable and efficient.
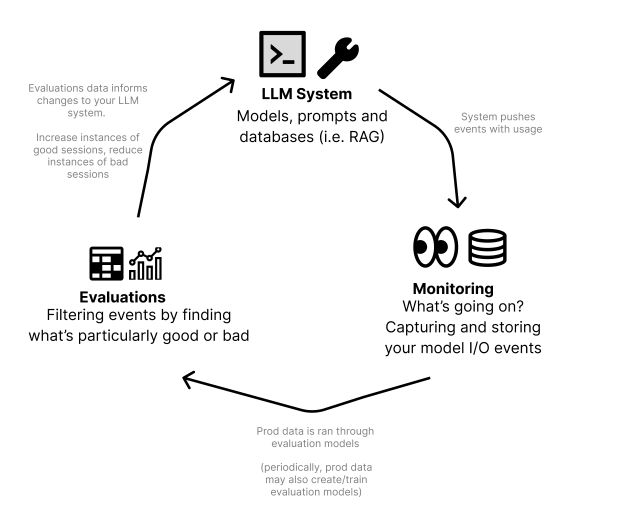
The ideal LLMOps stack accomplishes 2 goals. 1) Drives reliability, and 2) Creates self-enforcing feedback loops
This lets your LLMOps stack work for you, enabling your system to improve over time and setting your team up for success. Here’s how to set that up →
1. Initial launch: Observability + v1 evaluation
Ship early, and make sure you have tracking + monitoring in place.
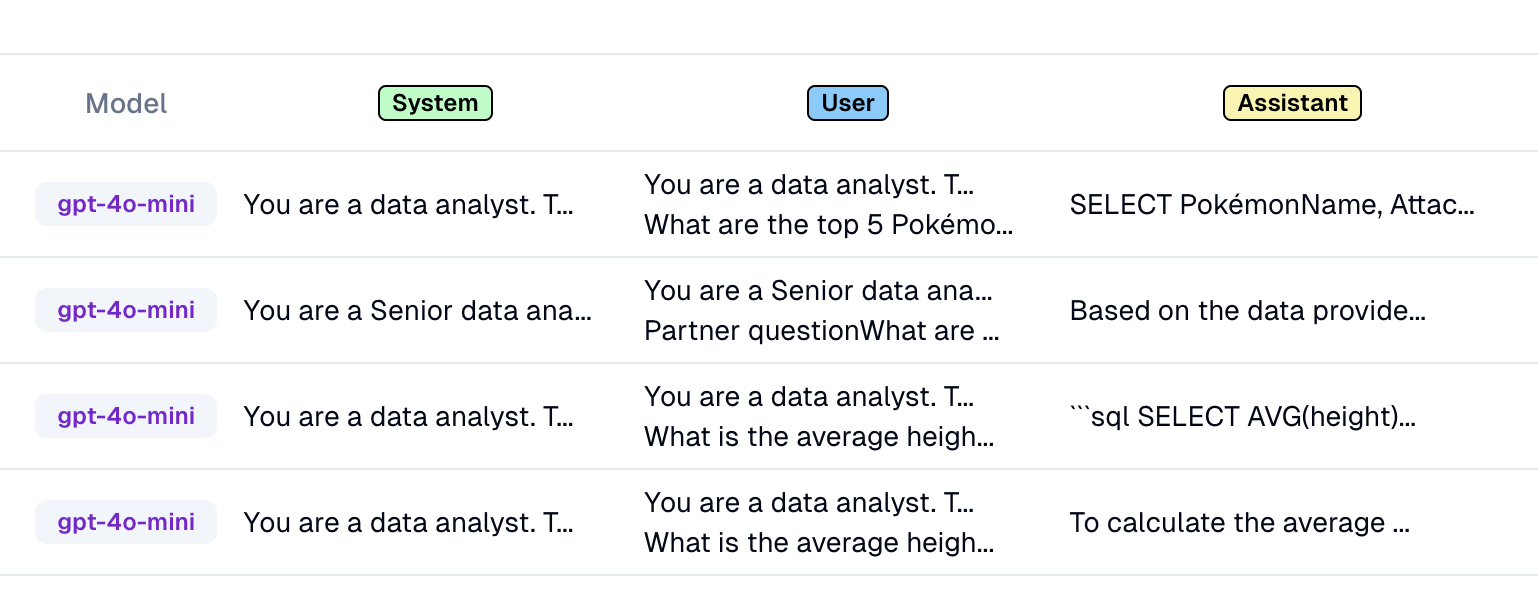
I’d also have a v1 evaluation model in place. This won’t be perfect, but it’s a starting place to iterate from.
I would set this up as an LLM as Judge prompt, using k-shot prompting to show the model how successful runs and outputs look like. I like this approach because it's easy to get started with and iterate on, and leverages the strengths of LLM as Judge (opens in a new tab).
If there are potential failures you know you want to avoid, you can also add these to your v1 evaluation model, and start gathering data on if these are a concern (and if so, how often they occur).
2. Rapid iteration: maturing your LLM and evaluations stack
As your system gets more usage it’s going to see more edge cases that you haven’t accounted for. As you’re finding these edge cases, I would continue to iterate your evaluations layer to account for the errors you're seeing.
During this time, your evaluations stack may mature from a single ‘vibe check model’, to a series of models checking for specific qualities. This can be great for leveraging the benefits of multiple LLM judges (opens in a new tab), and makes the 'error-specific' models more reliable.
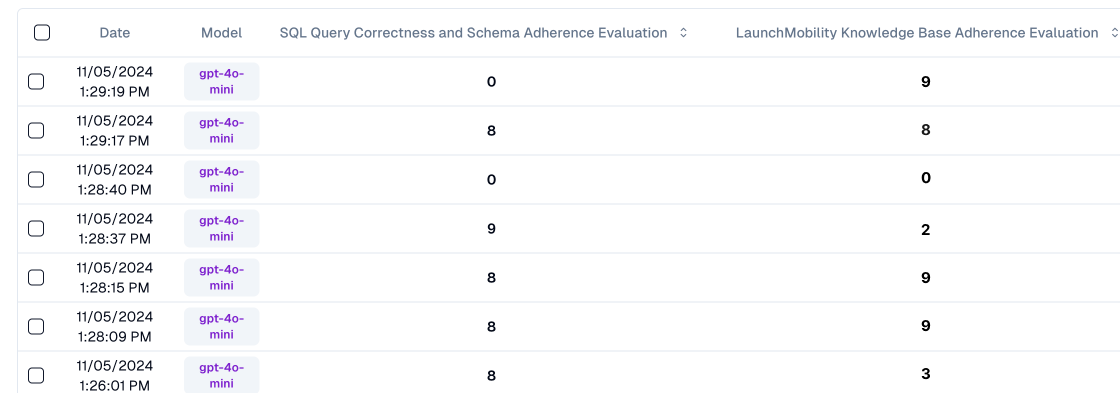
You should use these evaluation models to identify opportunities to improve your prompts/models. This can be to:
- More reliably produce the outputs you want (i.e. inter-response similarity)
- Improve the quality of each output (i.e. a higher ceiling)
- Raising the floor for failure cases (i.e. reducing the % of particular errors)
3. Steady state + feedback loops
Eventually, you'll reach a steady state where you are no longer finding new edge cases to prompt engineer your way out of. Are you done with evaluations now?
No! Here's how evaluations will still be critical for your LLMOps stack:
-
Identifying any impacts from exogenous changes - did you know the closed models, such as OpenAI and Anthropic, can just change their model weights without telling anyone? Evaluations are sometimes the only way of catching the impact of these changes on your system.
-
Validating the impact of any changes you’ve made. Say you just changed a prompt, how do you know if it ‘worked’ or not? Leaning on your evaluations will be key here. Your system is too mature to be making changes on 'vibes'. Use your evaluations to confirm - did your change make things better or worse? If 'better', how? Did you raise the ceiling/floor for a given response? Create more reliable outputs?
-
Feedback loops to build moats - if you’re interested in reducing your reliance on the large models and building your own moats, evaluations will be critical for building the training data sets for finetuning.
You could also do this for your eval models. Creating smaller eval models from your k-shot prompts can be cheaper and more effective in the long-run (opens in a new tab).
Periodically, you’ll want to use your evals to find ‘good’ sessions, and use that as your data layer for finetuning. Here’s an example of that for building a custom evaluation model, using human in the loop training data (opens in a new tab).
Happy building!
Now that you've got an idea of your LLMOps roadmap, the most important thing is to get started. If you're still worried about shipping your LLM products without strong LLMOps, feel free to grab some time with us (opens in a new tab) to chat through your concerns.
📖 If you liked this, sign up for our newsletter below. You can check out our other posts here (opens in a new tab).
© lytix