What’s the difference between LLM API Providers?

Does it matter what API provider I use?
⚡️ TLDR: Groq (opens in a new tab) is the winner in terms of both performance and pricing but realistically vendors will come and go, keeping your stack agnostic of vendor is one way to future proof yourself.
Something we are constantly exploring is seeing how we can save costs by switching between LLM API providers. Can we rip out our Bedrock integration and replace it with something like TogetherAI and suddenly reduce our cost by 33%? Is this possible ($0.3 for AWS and $0.2 for TogetherAI per 1M tokens)?
Context: For the purpose of this post we’ll be focusing on Llama-3 Instruct, but in general can generally be applied other foundational models.
Cost 💵
Starting with what could be seen as obvious, cost differs between providers, and some quite dramatically. Looking at a institutional provider such as AWS, we can see the cost 1M input tokens is $0.3 for the 8B param version of Llama.
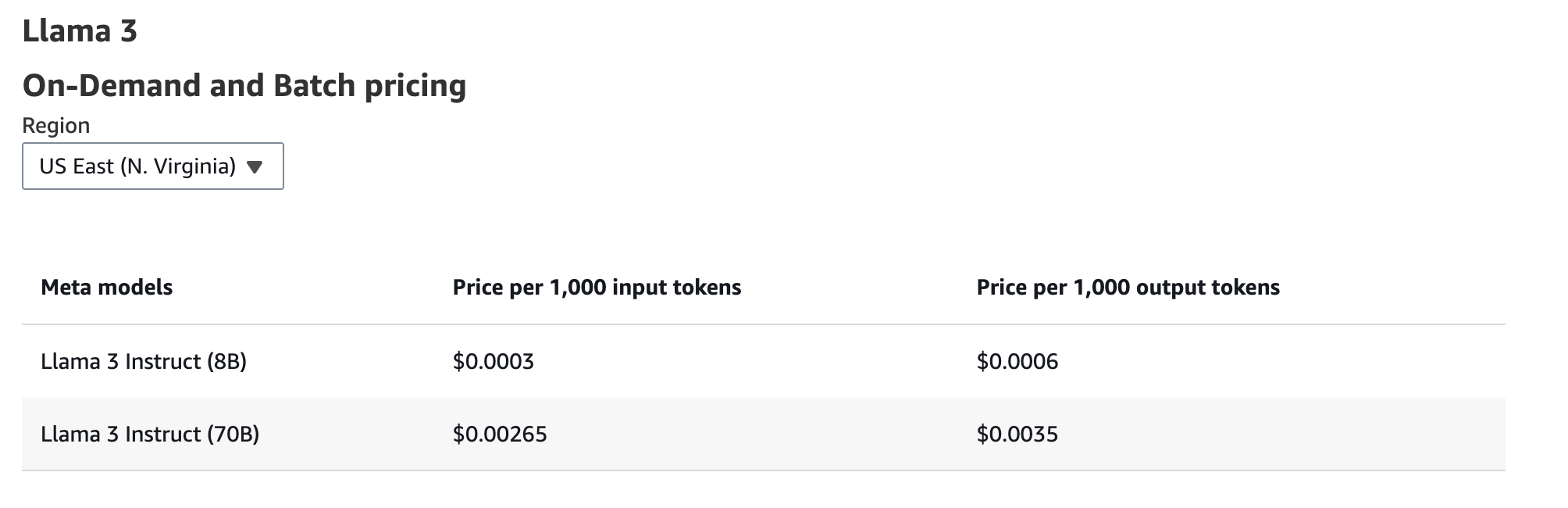
AWS Bedrock pricing page (opens in a new tab)
On the other hand, if we look at other providers such as TogetherAI you can see its clearly cheaper, $0.2 vs $0.3 so about a 33% cost reduction. At scale, you could imagine how this could translate to a meaningful difference.
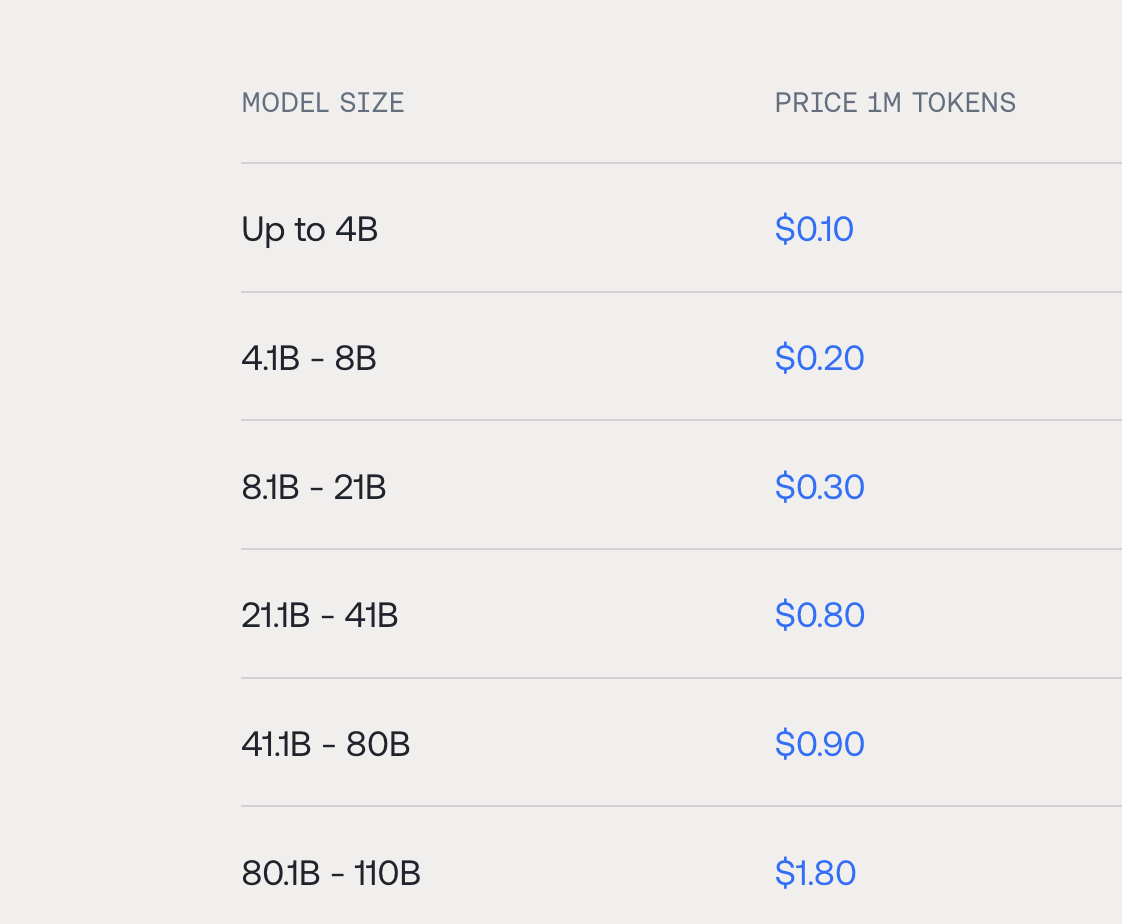
TogetherAI pricing page (opens in a new tab)
Looking a bit deeper, you can find providers that bring the cost down even further. For example, Groq advertise $0.05 per 1M input tokens.
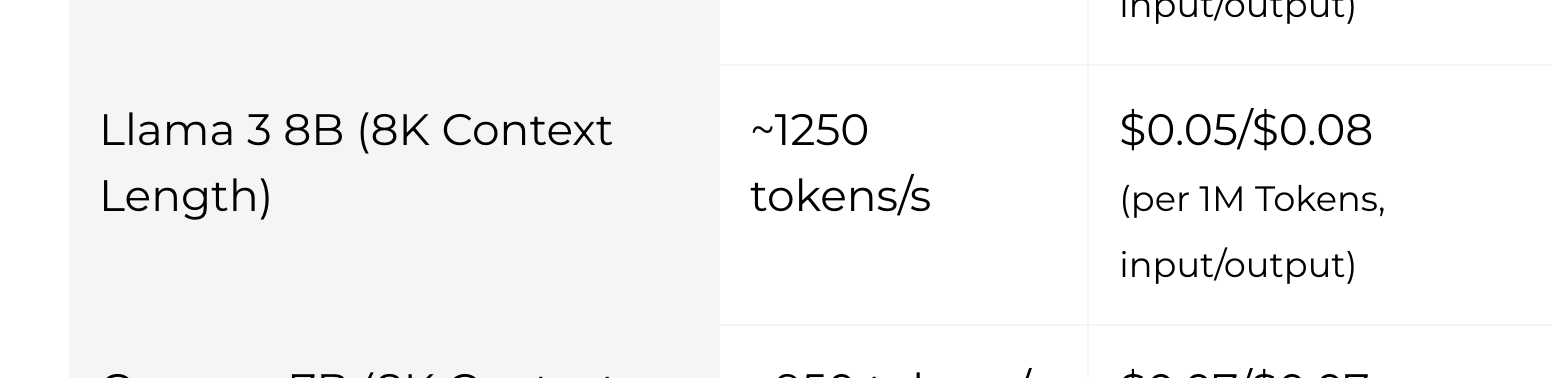
Groq pricing page (opens in a new tab)
So I should just move all my infrastructure to Groq…right?
Latency ⏰
Something that surprised us when looking deeper was the latency difference between API providers. Looking at baseline latency (how long to get any response), you start to see this difference: Groq and TogetherAI are cheaper then Bedrock, but are slightly slower.
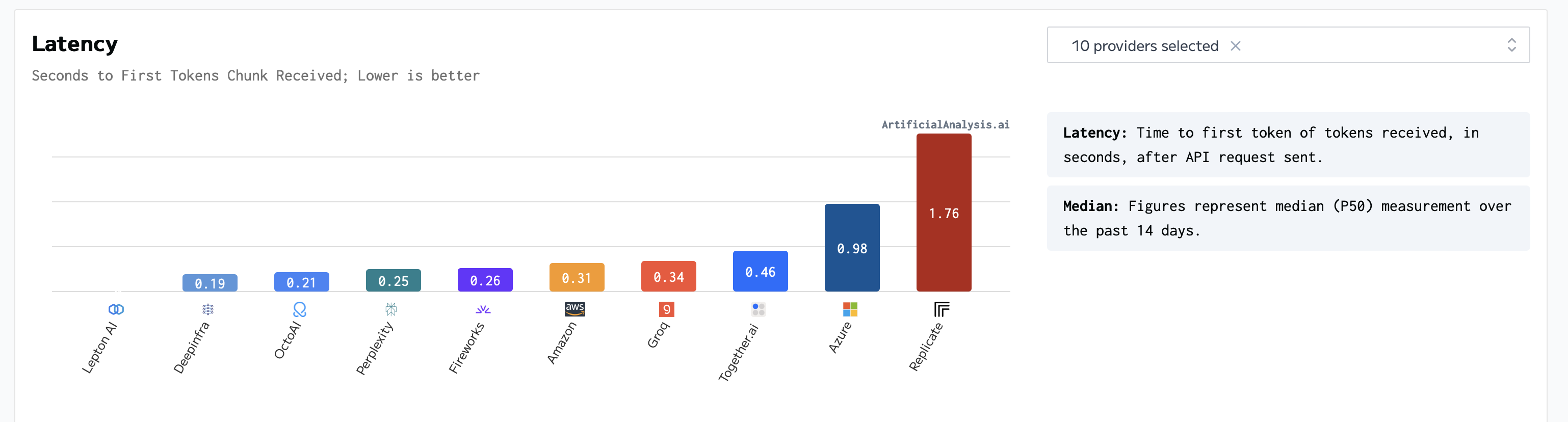
But what is 0.03 seconds right? Well this doesn’t show the full story. Time-to-first-token is a good metric, since it can be used as a proxy for user experience (how long is the user waiting after clicking ‘enter’), but for long responses, we would want to look at output speed (tokens-per-second)
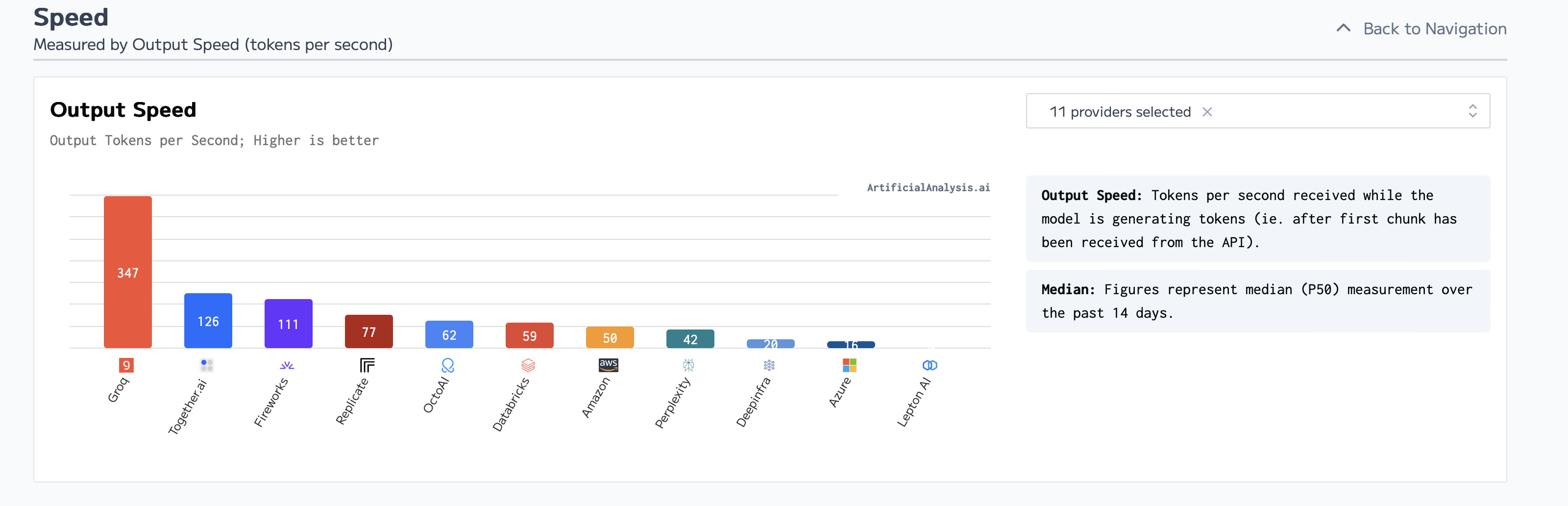
We can see in the above chart that Groq, well, “takes the cake”. With a 6x increase in output speed it is clearly the winner in terms of output speed. Sure you might be waiting an extra 0.03 seconds for the response, but after those 0.03 seconds Groq just demolishes the competition.
In addition this pattern continues, Groq historically shows to be much better compared to the competition:
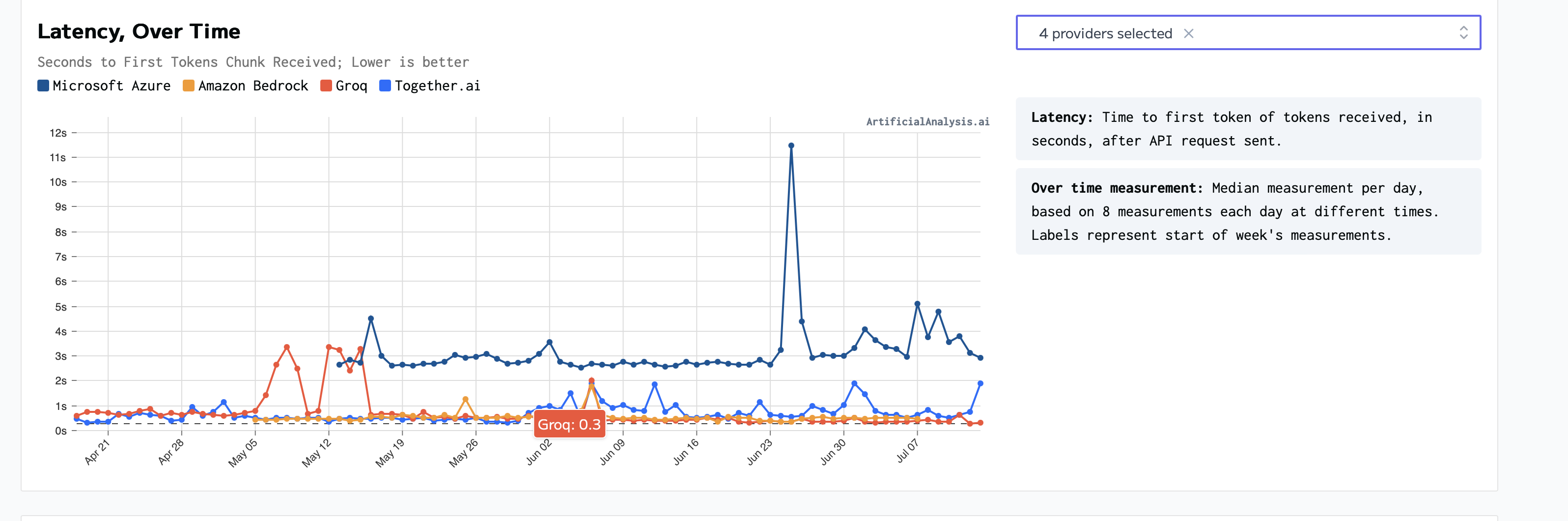
Why is Groq so "cracked"? 💭
Groq's performance advantages can be attributed to several key factors:
-
Specialized Hardware: Groq designs and uses its own custom-built processors specifically optimized for machine learning and artificial intelligence workloads. These processors, known as Tensor Streaming Processors (TSPs), are designed to handle massive parallelism and high-speed data transfer, which significantly speeds up computations.
-
Parallelism and Efficiency: The architecture of Groq's hardware allows for high levels of parallelism. This means that many operations can be executed simultaneously, which in turn reduces the overall time required for processing large-scale models and datasets.
-
Optimized Software Stack: Groq's software stack is tightly integrated with its hardware, ensuring that software optimizations can be directly translated into hardware performance gains. They own the whole stack (from hardware to the Saas), so they can optimize accordingly.
-
Energy Efficiency: By designing processors specifically for machine learning tasks, Groq can achieve higher energy efficiency. This translates for the end user as lower costs since their specialized hardware allows them to optimize their compute.
These combined factors enable Groq to deliver a significantly faster performance for large language model (LLM) APIs, compared to other providers who might rely on more generalized hardware and software solutions.
Potential Problems 👩💻
I can't speak too much here (and might do a separate blog post just on the subject), but it has been noted (opens in a new tab) that Groq hardware is best suited for a large number of users all accessing a single model. This has to due with Groq hardware lacking High Bandwidth Memory (HBM) and instead have a very small amount of ultra-fast SRAM (230mb).
Due to this, Groq requires a lot of their LPUs (language processing units) in order to serve a single model. Compare this to a Nvidia H200 GPU, which can serve these models efficiently.
This results in Groq hardware not being as practical for multiple models, or a number of fine tuned models which could have consequences for on-prem deployments where you can't rely on the thousands of users to take advantage of that hardware.
Conclusion ✍️
In the end what LLM provider you choose really depends on your specific situation. For example in our case, even though Groq is significantly cheaper we are fortunate enough to have AWS credits (can’t compete with free 🤑).
And as the tech continues to evolve other providers will slowly catch up to Groq in terms of latency and likely cost. Because of this provider lock-in should be top of mind. Building your entire infrastructure and codebase around a single provider is a recipe for a headache down the line.
That’s the beauty of these open foundational models, they allow the developer so much control and flexibility at the end of the day.
Checkout Optimodel here (opens in a new tab)
Because of this we’ve created an open source framework for managing not only multiple models, but multiple API providers as well, you can learn more about how we solved that here (opens in a new tab) or view the source code here (opens in a new tab). Currently we offer a way to manage Bedrock, TogetherAI, Groq and OpenAI in a single easy to use interface based on some of the learnings in this article. We also have a cloud option if you don’t want to host the server yourself 😊.
👨💻
📣 If you are building with AI/LLMs, please check out our project lytix (opens in a new tab). It's a observability + evaluation platform for all the things that happen in your LLM.
📖 If you liked this, sign up for our newsletter below. You can check out our other posts here (opens in a new tab).