Guaranteed Cheapest LLM Calls With No Vendor Lock-In

Note: we were originally excited about switching models based on cost. After some feedback from initial users, we learned that with the cost was not a primary issue, and would be even less of a concern as the LLMs get cheaper. We are now working on extending this model to help developers switch between models based on product and technical requirements. Watch this space for more! 🚀
How we built a framework to make this a reality
⚡️ TLDR: Switching between providers (e.g. AWS and TogetherAI) can save up to 1/3 on token costs ($0.2 vs $0.3/1M tokens). There are drawbacks such as latency, but those can be mitigated with a smart framework that factors that in when making LLM calls. With the ability to add new and custom providers, you can guarantee you’re making the cheapest LLM call with no vendor lock-in. Found a cheaper provider? Just add it ✅
We obsess over token cost and what they mean in the long run. Being in the AI space a question we often see is ‘how are you going to scale with OpenAI?’ since this can become a huge scaling cost if your infrastructure relies too much on OpenAI costs. A valid question and something that I’ve put a lot of thought (opens in a new tab) into. As we start building out our LLM infrastructure, I ran into 3 problems that I couldn’t find (or more likely didn’t find) a solution to:
- There is a price difference between providers that generally results in differing compute (latency):
- There is usually a tradeoff of speed when it comes to this which should be noted and is discussed further. But looking at data (opens in a new tab) available, choosing a different provider can influence the price. And when the difference in price can be up to 33% (e.g $0.2 vs $0.3), with scale this could be more important. In any case, an ideal framework would try to abstract this away as much as possible.
- I often found myself trying to haphazardly implement a fallback mechanism to use larger models if smaller ones could not solve the problem.
- Since the price difference between larger models and smaller ones again can be significant (opens in a new tab), I would much rather lean on smaller cheaper models as much as possible. But there are times those models do fail, and I often would just fallback to larger ones when needed. An ideal framework would handle this for me.
- Abstraction is tight, but I do need some control
- I always want to use the cheapest provider as long as my product doesn’t suffer. Similar with price, different providers do offer different speeds (opens in a new tab). Often I don’t care about latency, especially if its a background task. But there are situations where speed does matter (for example when responding to a user query). An ideal framework would again abstract the difficulties of choosing a provider, but allow me to dictate when speed is a priority.
So I have a goal, I don’t want to put together multiple frameworks to achieve this, I would love for a single endpoint abstract and handle this for me. Let’s start building 🧱
I first set out to tackle my cost dilemma. When presented with multiple providers, choose the cheapest one. We know at the end we’ll want this to be config driven, so I started by defining that to start:
{
"availableModels": {
"together": [
{
"name": "llama_3_8b_instruct",
"pricePer1M": 0.2,
"speed": 119.88,
"maxGenLen": 4000
},
{
"name": "llama_3_70b_instruct",
"pricePer1M": 0.9,
"speed": 270.17,
"maxGenLen": 4000
}
],
"aws-bedrock": [
{
"name": "llama_3_8b_instruct",
"pricePer1M": 0.3,
"speed": 78.91,
"maxGenLen": 8192
},
{
"name": "llama_3_70b_instruct",
"pricePer1M": 3.075,
"speed": 48.31,
"maxGenLen": 8192
}
]
}
}This JSON keeps track of all available providers, and for each provider what models are offered along with their metadata (price, speed, etc.).
Note: For now I’ve pulled and defined speed from artificialanalysis.ai (opens in a new tab), but I do want to acknowledge that this part of the project still needs refining since there are factors like server location that also play a role.
With this I write a simple algorithm that worked as follows:
allAvailableProviders = getAllAvailableProviders(data)- Get all available providers (e.g. in the config above,
aws-bedrock, andtogether - This function should also factor in what providers are configured correctly. For example, if the config says
aws-bedrockbut there are no AWS credentials present, it should not be an option.
- Get all available providers (e.g. in the config above,
orderedProviders = orderProviders(allAvailableProviders, data)- Order the providers given the criteria present. Without getting into the code (opens in a new tab), the doc-string reads as follows:
def getOrderProviders(allAvailableProviders: list, body: QueryBody) -> list: """ Given a list of providers, place them in sorted order using the following logic: - Speed is most important to us, if the user says they want the fastest, always pick the fastest - Otherwise default to cost, we'd like to save money as much as we can """- Generally this just goes over the mantra outlined above, cost is the only thing that matters unless we specifically asked for speed
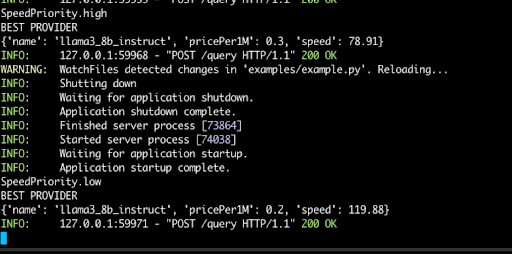
With that you have a sorted list of providers available, now just pick the first one and that’s where we should execute our LLM call. Let’s go through an example. Let’s say I am making a call as follows, given the example config above, depending on the variable speedPriority, together is the cheaper choice, but aws-bedrock is the faster choice.
response = await queryModel(
model=ModelTypes.llama_3_8b_instruct,
messages=[
ModelMessage(
role="system",
content="You are a helpful assistant. Always respond in JSON syntax",
),
ModelMessage(role="user", content=prompt),
],
speedPriority=“low", // What is this was “high"
)And as expected, if specify that speed is important, it picks the best provider as aws-bedrock with a pricePer1M of 0.3, but if you set it to low, we get together with a pricePer1M of 0.2 🍻
We’re almost done. As mentioned in the start, this framework should abstract the annoying parts of implementing fallbacks/retries. For example if you expect the model to return JSON, we’d like it to automatically retry on a bigger model (e.g. 8B param version of Llama should fallback to the 70B param version).
To achieve this, we added an optional validator parameter on the clients side. This allowed the end user to supply a function that would return a boolean pass/failed in order to indicate if the output was valid.
async def queryModel(
model: ModelTypes,
messages: list[ModelMessage],
speedPriority: SpeedPriority = None,
validator: Callable[[str], bool] = None,
fallbackModels: list[ModelTypes] = [],
maxGenLen: int = 1024,
temperature: float = 0.2,
):
"""
Query a model
@param model: The model to use
@param messages: The messages to send to the model
@param speedPriority: The speed priority of the query
@param validator: A function that takes in the model output and returns a boolean if it passed/failed validation
@param fallbackModels: A list of models to use if the first model fails.
"""One consequence (but honestly something I wanted) is that the input format (e.g. messages) needs to be standard across models. Some providers do some of this for you automatically. For example together (opens in a new tab) expects messages in {role: string; content: string}[] type format. You can see llama has a specific way of translating that to their input format:
finalPrompt = "<|begin_of_text|>"
for message in messages:
finalPrompt += f"<|start_header_id|>{message.role}<|end_header_id|>{message.content}<|eot_id|>"
finalPrompt += "<|start_header_id|>assistant<|end_header_id|>"I love this, it makes developing a lot easier, and makes me think about small idiosyncrasies when trying different models. I acknowledge that this might not work for everyone (and think there might be a rawInput type middle ground that could be achieved), but this works for us right now.
This just means each provider should expect a standard message type ({role: string; content: string}[]), and they need to ‘translate’ however they need to. The end user can just use a single syntax to communicate across all models.
And with that the initial MVP was finished! The project (opens in a new tab) worked, it could be installed via pip and was decently easy to set up.
But as our company navigates a pivot, it was at this point we realized we could also offer this as a feature on our platform. The rest of the article will go into how we modified the code to support both these use cases and dive more into the product we ended up offering, but incase that’s not your vibe; thanks for getting this far and I strongly encourage you to check out the open source repo here (opens in a new tab) 🚀.
Turning It Into a Product
When thinking about how to make this easier to use, the big problem for us was credentials. Me and my co-founder would constantly have to be sending API keys back and forth, or updating IAM permissions in order to get things working. What worked on one computer always took a bit to get set up on the other computer.
We started with the providers together and aws-bedrock. AWS initially seemed too challenging to tackle since we initially used boto3 to automatically source credentials from the user running the program. But together was very straight forward with a simple API_KEY pattern (eventually we were able to get AWS working along with adding OpenAI).
The high level framework can be seen below. The idea is to continue to use the optimodel-server as you would as a normal user, but let our platform, Lytix, sit in between the server and users.
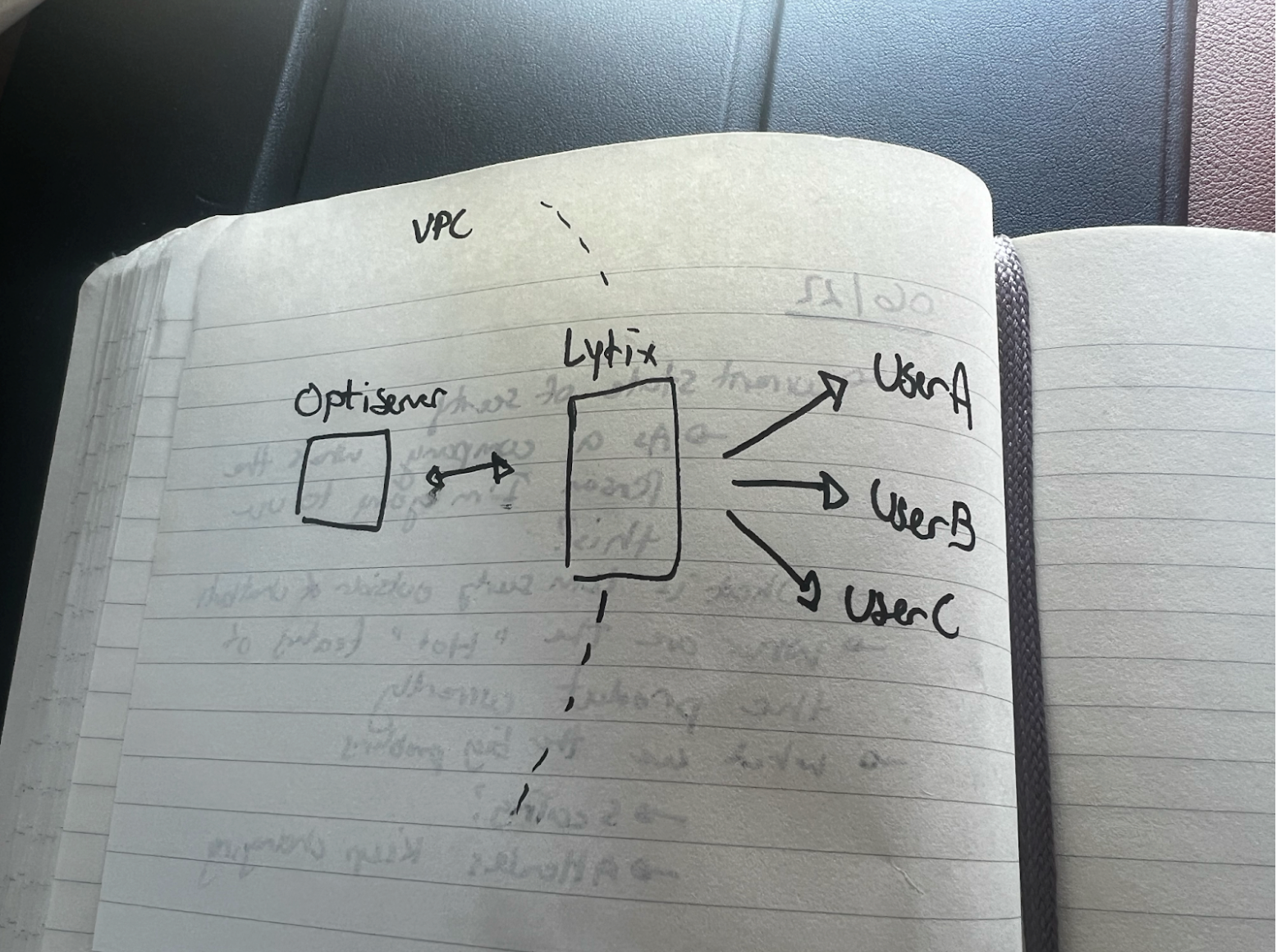
Credentials for each user will be stored on the Lytix platform (that way only one user in the team needs to set up the API keys one time), and will be served to the server on every request. The credentials will be added as a payload in the request to the server and change depending on what team is making the request.
class QueryBody(BaseModel):
messages: list[ModelMessage]
modelToUse: str
speedPriority: SpeedPriority | None = None
temperature: float = 0.2
maxGenLen: int = 1024
"""
If we are running in SAAS mode, we'll expect each request to bring their
own credentials
"""
credentials: (
list[TogetherAICredentials | OpenAICredentials | AWSBedrockCredentials] | None
) = NoneWe didn’t want to affect the running of the server normally. To get around that we implemented a OPTIMODEL_SAAS_MODE envvar to control if this ran on ‘single-user-mode’ where credentials were sourced from the machine, or ‘saas-mode’ where credentials were expected in every request.
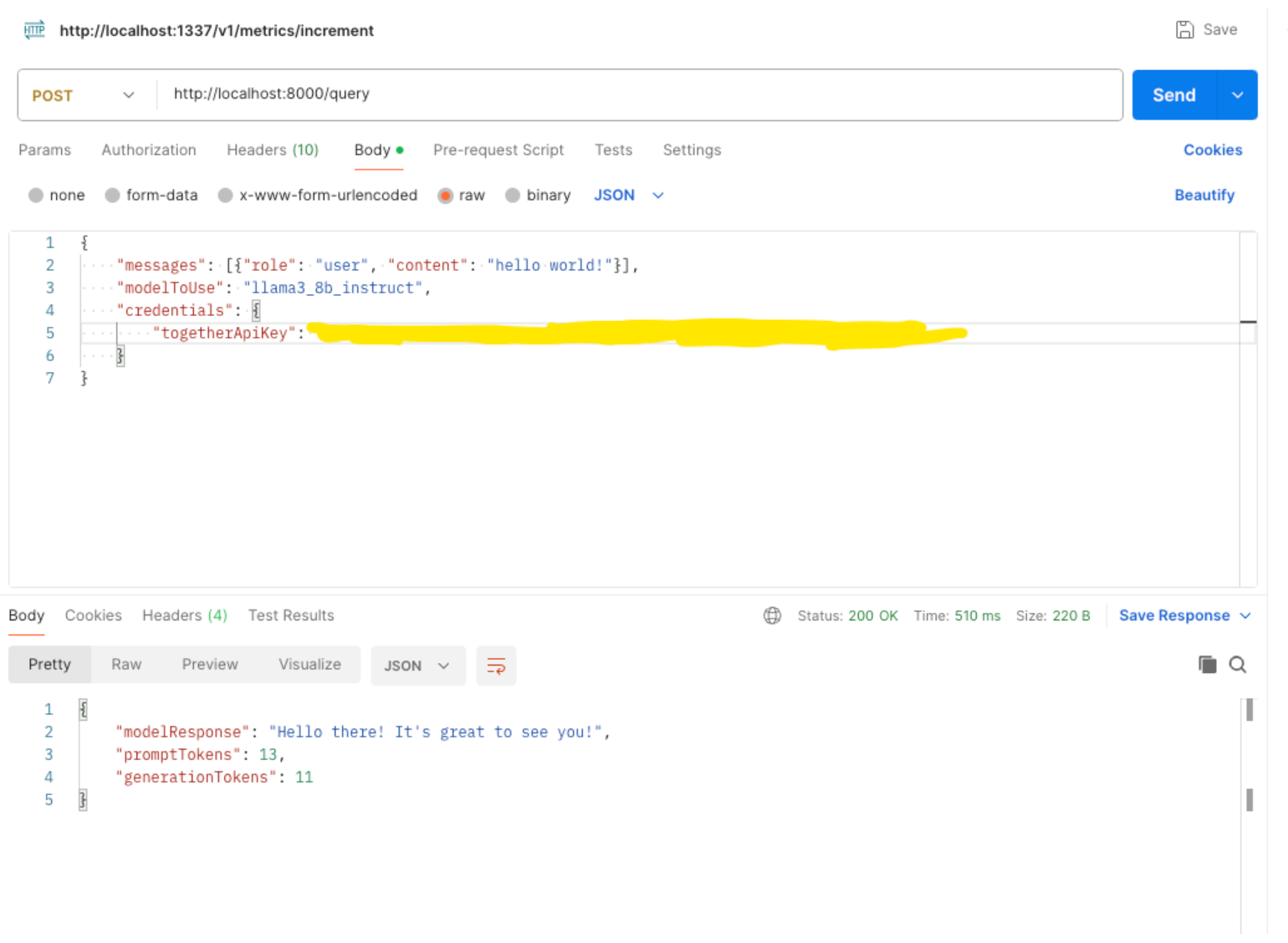
And you can see here an example post request. You can pass the tokens in the request of the body itself:
And then we’re done! It was just a bit of UI work that was needed to source the credentials from a Lytix user initially:
And requests will automatically be proxied through Lytix
> export LX_API_KEY=<123>
> pip3 install optimodel
> vim example.py
> python3 example.pyAnd you can start making queries like the ones seen above (as long as you’ve got the right providers configured)! Since our platform is designed for analytics, it was straightforward to also start collecting cost and token usage data to bubble up to users.
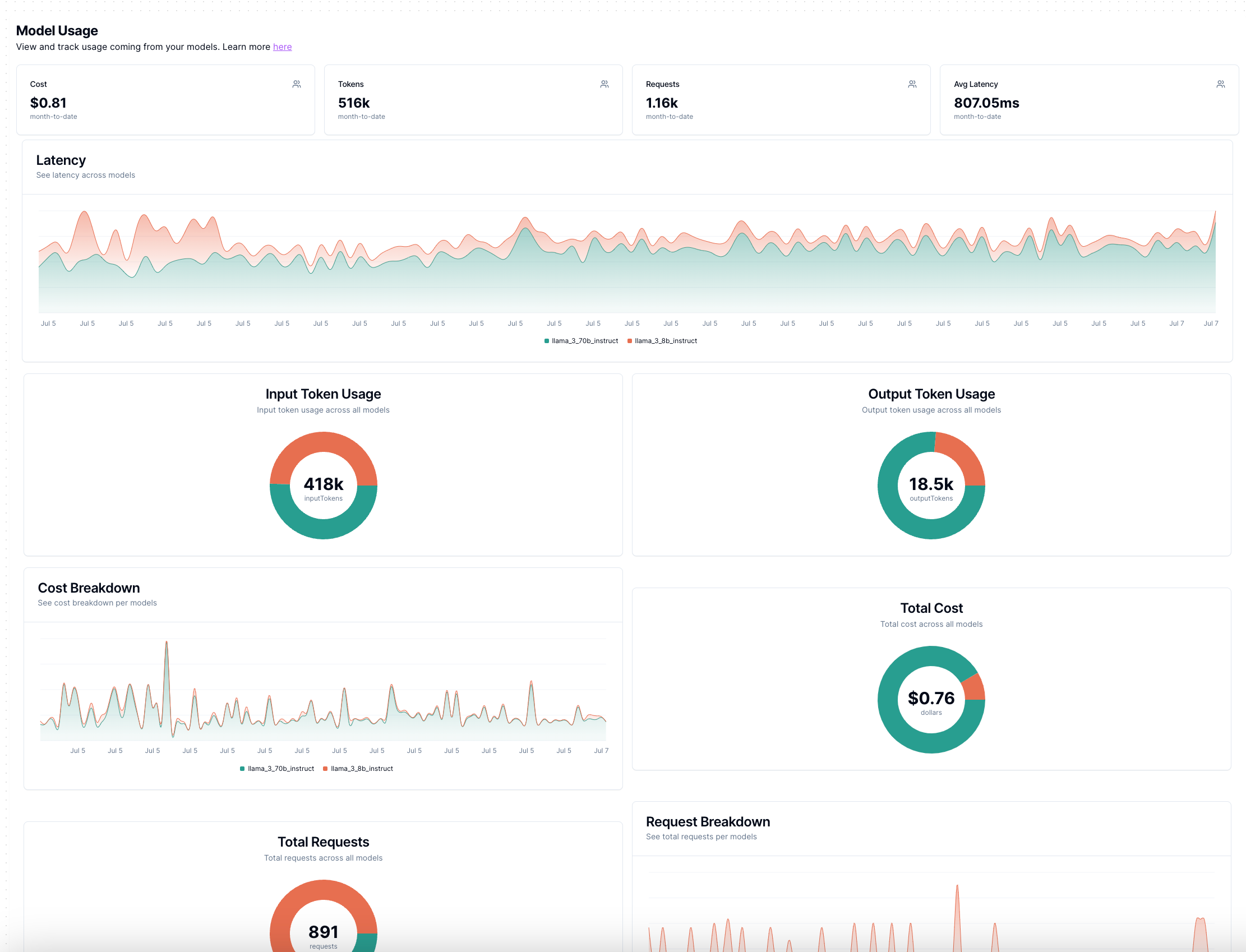
And with that a feature was launched (or is being launched via this post 😅)! Looking to the future (depending on reception), we do plan on adding more providers as there are some that can be even more competitive in pricing such as groq (opens in a new tab) and we’ve already added OpenAI and AWS support on Lytix.
If you are curious on getting started and want a kick ass platform to start collecting product analytics (or analytics in general) on your LLMs check out the optimodel Quickstart guide here (opens in a new tab)
👨💻
📣 If you are building with AI/LLMs, please check out our project lytix (opens in a new tab). It's a observability + evaluation platform for all the things that happen in your LLM.
📖 If you liked this, sign up for our newsletter below. You can check out our other posts here (opens in a new tab).