Cost Of Self Hosting Llama-3 8B-Instruct

How much does it cost to self host a LLM?
⚡️ TLDR: Assuming 100% utilization of your model Llama-3 8B-Instruct model costs about $17 dollars per 1M tokens when self hosting with EKS, vs ChatGPT with the same workload can offer $1 per 1M tokens. Choosing to self host the hardware can make the cost <$0.01 per 1M token that takes ~5.5 years to break even.
A question we often get is how do you scale with ChatGPT. One thing we wanted to try is to determine the cost of self hosting an open model such as Llama-3.
Determining the best hardware
Context: All tests were run on a EKS cluster. Each test was allocated the resources of the entire node, nothing else was running on that node other than system pods (prometheus, nvidia-daemon, etc.)
We first wanted to start small, can we run it on a single Nvidia Tesla T4 GPU? I started with AWS’s g4dn.2xlarge instance. Its specs were as follows (source (opens in a new tab)):
- 1 NVidia Tesla T4
- 32GB Memory.
- 8 vCPUs
The short answer is that running either the 8B param or the 70B param version of Llama 3 did not work on this hardware. We initially tried the 70B param version of Llama 3 and constantly ran into OOM issues.
We then sobered up and tried the 8B param version. Although this time we was able to get a response, generating the response took what felt like ~10 minutes. I checked nvidia-smi and the single GPU was being used, it just wasn’t enough.
For context 8B vs 70B refers to the parameters in the model and generally translate to performance of the model. The advantage of the 8B param is its small size and resource footprint.
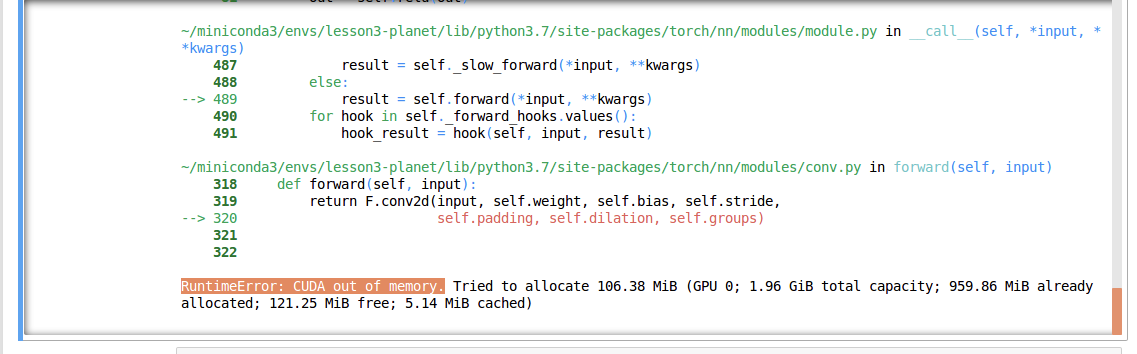
So I decided to switch to the g4dn.16xlarge instance type. The specs of that were as follows (source (opens in a new tab)):
- 4 NVidia Tesla T4s
- 192gb memory
- 48 vCPUs
Initial Implementation
My initial implementation involved trying to copy and paste the code present on the llama-3 hugging face (see (opens in a new tab))
import transformers
import torch
model_id = "meta-llama/Meta-Llama-3-8B-Instruct"
pipeline = transformers.pipeline("text-generation", model=model_id, model_kwargs={"torch_dtype": torch.bfloat16}, device_map="auto")
import time
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
terminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
now = time.time()
print(f"Starting pipeline now: {now}...")
outputs = pipeline(
messages,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.8,
top_p=0.9,
)
modelOutput = outputs[0]["generated_text"][-1]
later = time.time()
difference = int(later - now)
print(f"Prompt took: {difference} seconds to respond: {modelOutput}”)These results seemed a lot more promising as the response time lowered from ~10m to sub 10 seconds consistently.

I was able to get a response in a much more reasonable 5-7 seconds. At this point I wanted to start calculating the cost of this request.
g5dn.12xlarge costs $3.912 per hour on demand (see (opens in a new tab)).
If we assume a full month of use, that costs:
Per hour cost * 24 * 30 = Total Cost
$3.912 * 24 * 30 = $2,816.64I had trouble with getting the token count in hugging face so ended up using llama-tokenizer-js (opens in a new tab) to get an approximation of tokens used.
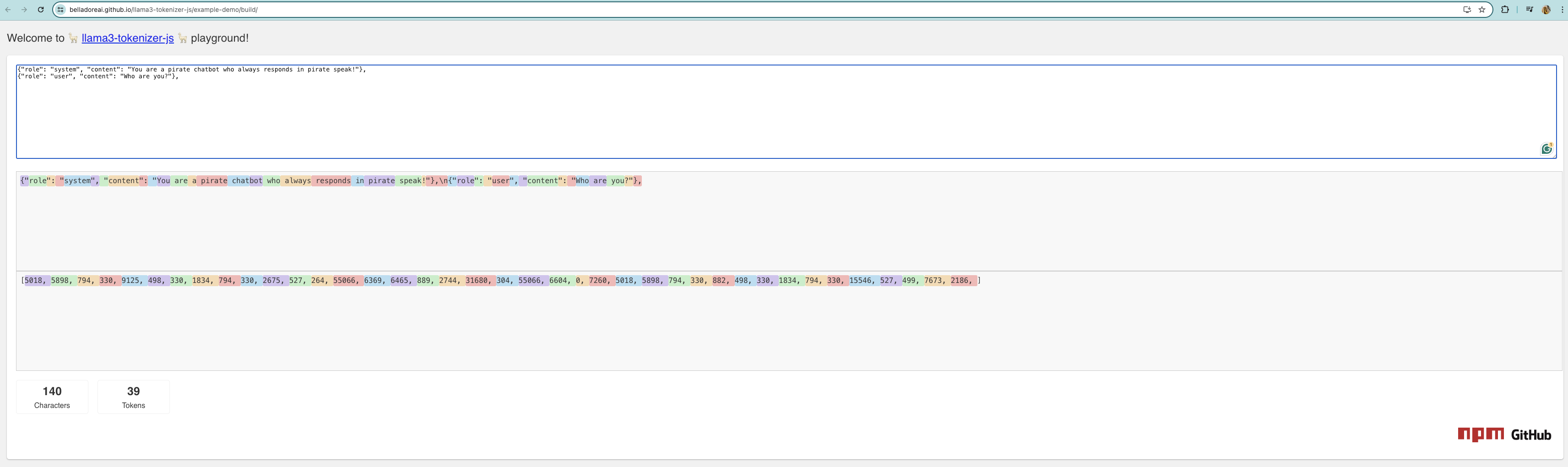
Note: This ended up being incorrect way of calculating the tokens used.
If we look at this result, we assume we used 39 tokens over ~6 seconds. Assuming Im processing tokens 24/7, extrapolating that we get:
39 tokens over 6 seconds = 6.5 tokens/sWith 6.5 tokens per second, over the month I can process:
Tokens Per Second * 60 (to get to minutes) * 60 (to get to hours) * 24 (to get to days) * 30 (to get to month) = Total Tokens Per Month
6.5 * 60 * 60 * 24 * 30 = 16,848,000With 16,848,000 tokens per month, every million tokens costs:
Total Cost / Total Tokens processed => Cost per token * 1,000,000 => Cost Per 1M token
( 2,816.64 / 16,848,000 ) * 1,000,000 = $167.17😵Yikes. It is not looking good. Lets compare this to what ChatGPT 3.5 can get us.
Looking at their pricing (opens in a new tab), ChatGPT 3.5 Turbo charges $0.5 per 1M input token, and $1.5 per 1M output token. For sake of simplicity, assuming an average input:output ratio, that means per 1M tokens they charge $1 and thats the number to beat. Far from my $167.17.
Realization Something Was Wrong
At this point I felt I was doing something wrong. Llama 3 with 8B params is hard to run, but I didn’t feel it should be this hard, especially considering I have 4 GPUs available 🤔.
I decided to try to use vLLM to host an API server instead of attempting to do it myself via hugging face libraries.
This was dead simple and just involved me installing ray and vllm via pip3 and then changing my docker entry point to:
python3 -m vllm.entrypoints.openai.api_server --model meta-llama/Meta-Llama-3-8B-Instruct --tensor-parallel-size 4 --dtype=half --port 8000
Specifically noting that I call —tensor-parallel-size 4 to enforce that we use all 4 GPUs.
Using this got significantly better results.
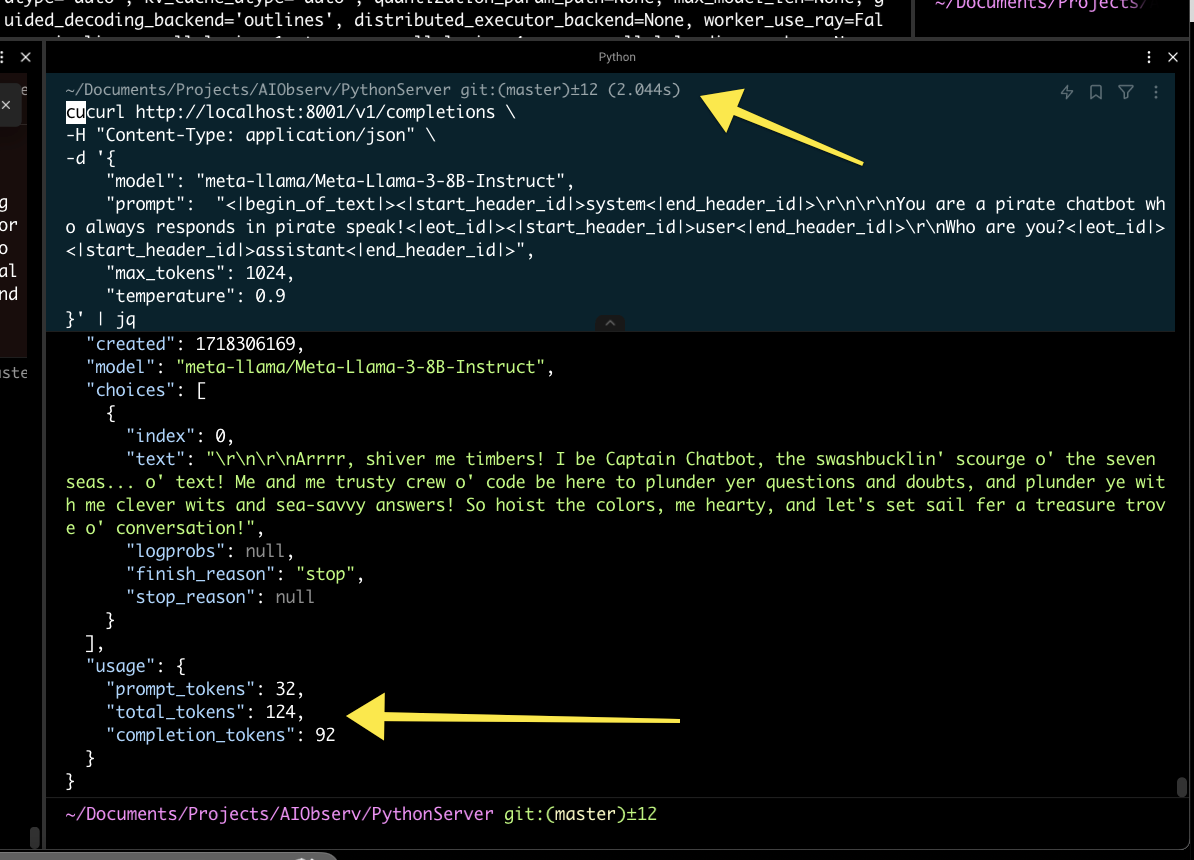
In this example you can see the query took 2044ms to complete. This was also the time I realized my previous method of calculating token usage was incorrect. vLLM returned the tokens used which was perfect.
Going back to cost, now we can calculate tokens per second:
Total Tokens / Total Time => Token/s
124/2.044 => 60.6 Token/sAgain assuming I produce tokens 24/7, this means that I can ingest a total of:
Tokens Per Second * 60 (to get to minutes) * 60 (to get to hours) * 24 (to get to days) * 30 (to get to month)
60.6 * 60 * 60 * 24 * 30 = 157,075,200Which means the cost per 1 million tokens would cost me:
Total Cost / Total Tokens processed => Cost per token * 1,000,000 => Cost Per 1M token
( 2,816.64 / 157,075,200 ) * 1,000,000 = $17.93Unfortunately this is still not below the value that ChatGPT offers, you’d lose about $17 a day 😭
An Unconventional Approach
Instead of using AWS another approach involves self hosting the hardware as well. Even after factoring in energy, this does dramatically lower the price.
Assuming we want to mirror our setup in AWS, we’d need 4xNVidia Tesla T4s. You can buy them for about $700 dollars on eBay
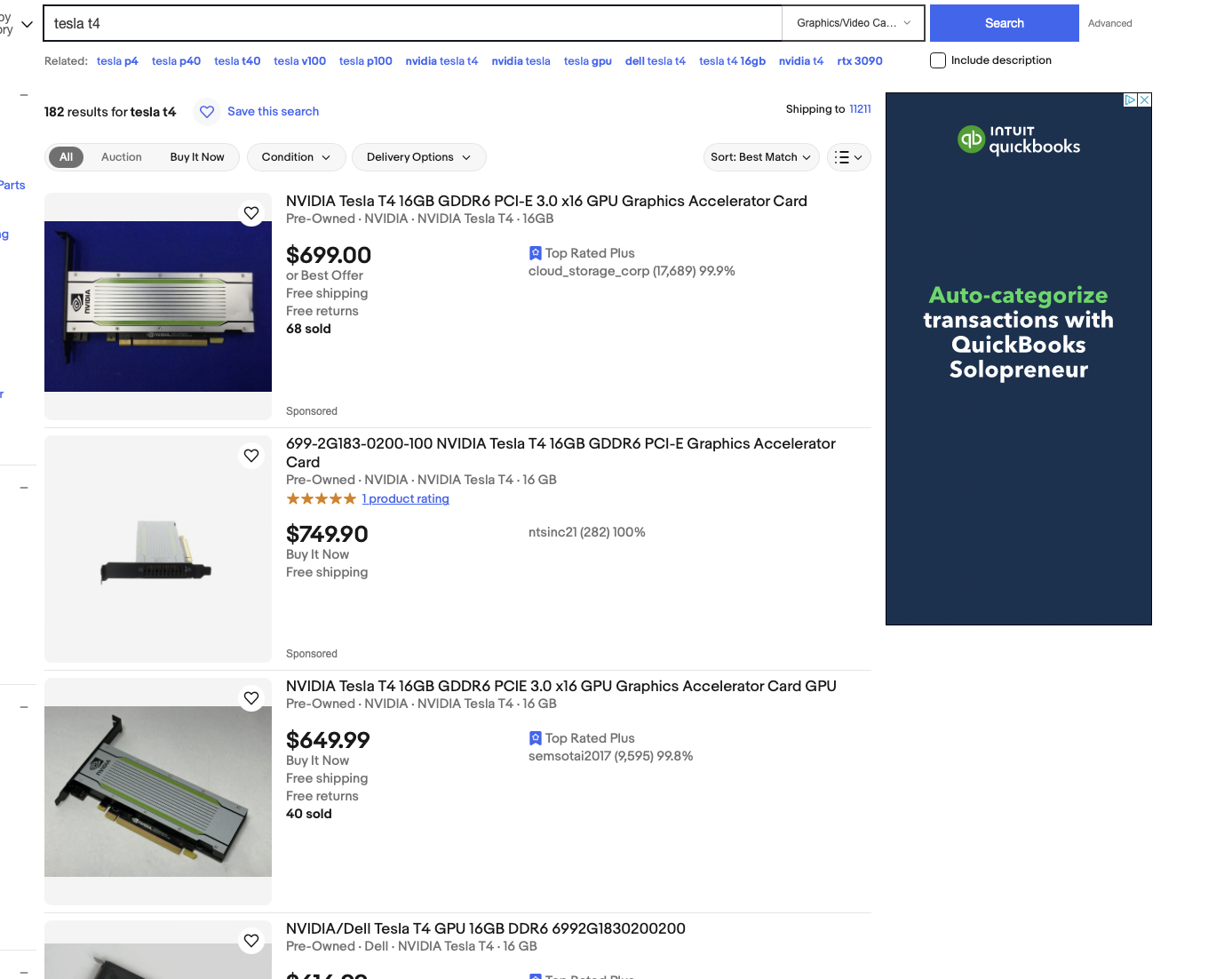
Add in $1,000 to setup the rest of the rig and you have a final price of around:
$2,800 + $1,000 = $3,800If we calculate energy for this, we get about ~$50 bucks. I determined power consumption by 70W per GPU + 20W overhead:
After factoring in the ~$3,800 fixed cost, you have a monthly cost of ~$50 bucks, lets round up to ~$100 to factor any misc items we might have missed.
Re-calculating our cost per 1M tokens now:
Total Cost / Total Tokens processed => Cost per token * 1,000,000 => Cost Per 1M token
( 100 / 157,075,200 ) * 1,000,000 = $0.000000636637738Which is significantly cheaper than our ChatGPT costs.
Trying to determine when you’d break even, assuming you want to produce 157,075,200 tokens with ChatGPT, you’re looking at a bill of:
157 * Cost per 1M token ~= 157 * $1 = $157You have a fixed cost of ~$100 a month, which results in a ‘profit’ of $57. To make up your initial server cost of $3,800, you’d need about 66 months or 5.5 years to benefit from this approach.
Although this approach does come with negatives such as having to manage and scale your own hardware, it does seem to be possible to undercut the prices that ChatGPT offer by a significant amount in theory. In pracitice however, you'd have to evaluate how often you are utilizing your LLM, these hypotheticals all assume 100% utilization which is not realistic and would have to be tailord per use case.
👨💻
📣 If you are building with AI/LLMs, please check out our project lytix (opens in a new tab). It's a observability + evaluation platform for all the things that happen in your LLM.
📖 If you liked this, sign up for our newsletter below. You can check out our other posts here (opens in a new tab).