Interactive and Personalized YC Interview Bot
⚡️ TLDR: We built (opens in a new tab) a interactive AI powered interviewer inspired by Paul Graham. It gives you personalized and targeted questions based on your YC application.
When we first interviewed for YC's Winter '24 batch, we found this (opens in a new tab) Paul Graham simulator incredibly helpful. YC interviews are famously incredibly short, only 10 minutes. That means you have to answer each question within ~10 seconds. This helped us organize our thoughts, and practice delivering our answers quickly despite the time pressure.
One problem we found however, was knowing which questions they would ask us specifically, given our company context. So we had to guess which questions they would ask us, and prepare accordingly. This meant we wasted time preparing for questions they wouldn't ask us, and that we were anxious about getting asked a question we thought would be 'irrelevant'.
What we wanted was a simulator that would look at our application, and ask us questions accordingly (the way the YC interview works).
So we built it! Here's the output of our weekend company hackathon 🚀 We wanted to give back to the community, so we made this available for everyone.

How does it work?
At its core this is a really simple RAG pipeline. The high level idea is as follows:
First we need to figure out ‘how Paul Graham thinks’. To do this we found a public formatted dataset of all his essays he wrote here (opens in a new tab).
We then embedded and loaded all that data into our Pinecone vector store, this way we can lookup based on similarity to application what Paul Graham might be thinking.
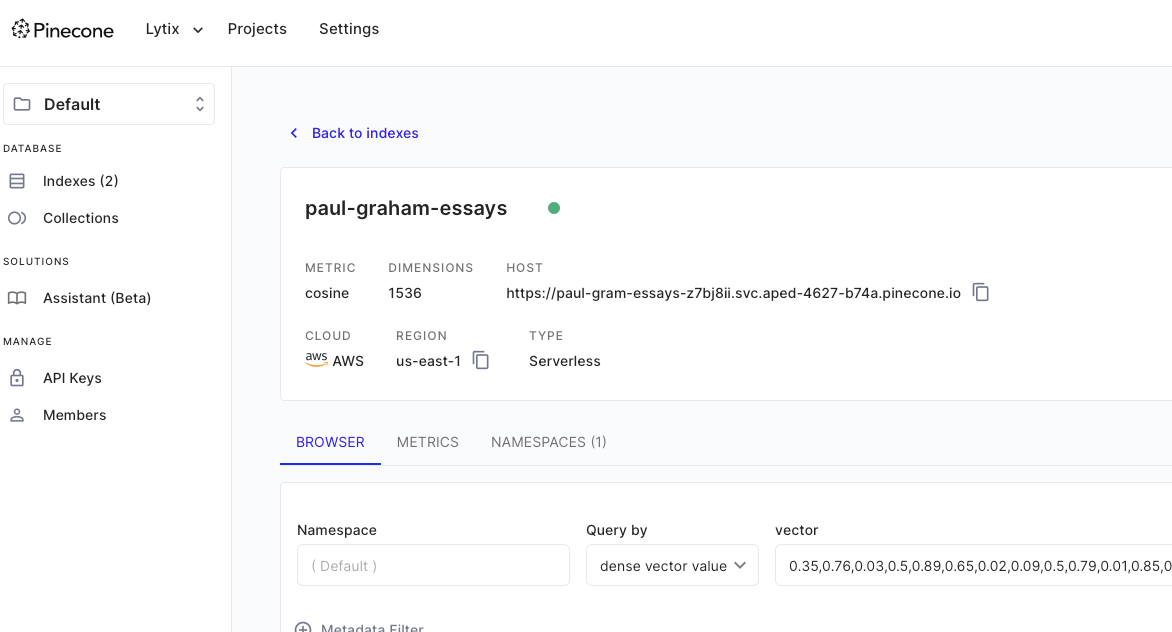
Now, our LLM has access to everything PG knows about how to think about, evaluate and build startups 👀
Now we need to do some prompt engineering to figure out the best way to add this context to our prompt.
Our first problem is YC applications can get really long 😅, and our context windows for the models we want to use are too small to pass in all that information. So we had to split up the logic as follows
-
First, we extract all the text from the application you upload, and pass that to a model that summarizes it into 500 words or less.
-
Next, we then use that concise summary to ‘RAG’ our Pinecone database to get the top 3 most relevant excerpts from PG's essays.
-
Finally we pass the summarized application and the relevant essay excerpts, to our final model and ask it to give us questions that Paul Graham might ask.
The final prompt looked something similar to this
finalPrompt = f"Given a summary of an application to a startup accelerator, please come up with a list of questions to ask the applicant to answer. Here is the summary: {summaryFormatted}. You should ask the questions in the format of Paul Graham, here are some examples of how he speaks: {paulGrahamEssays}. Only return JSON list of questions."And here's the result!
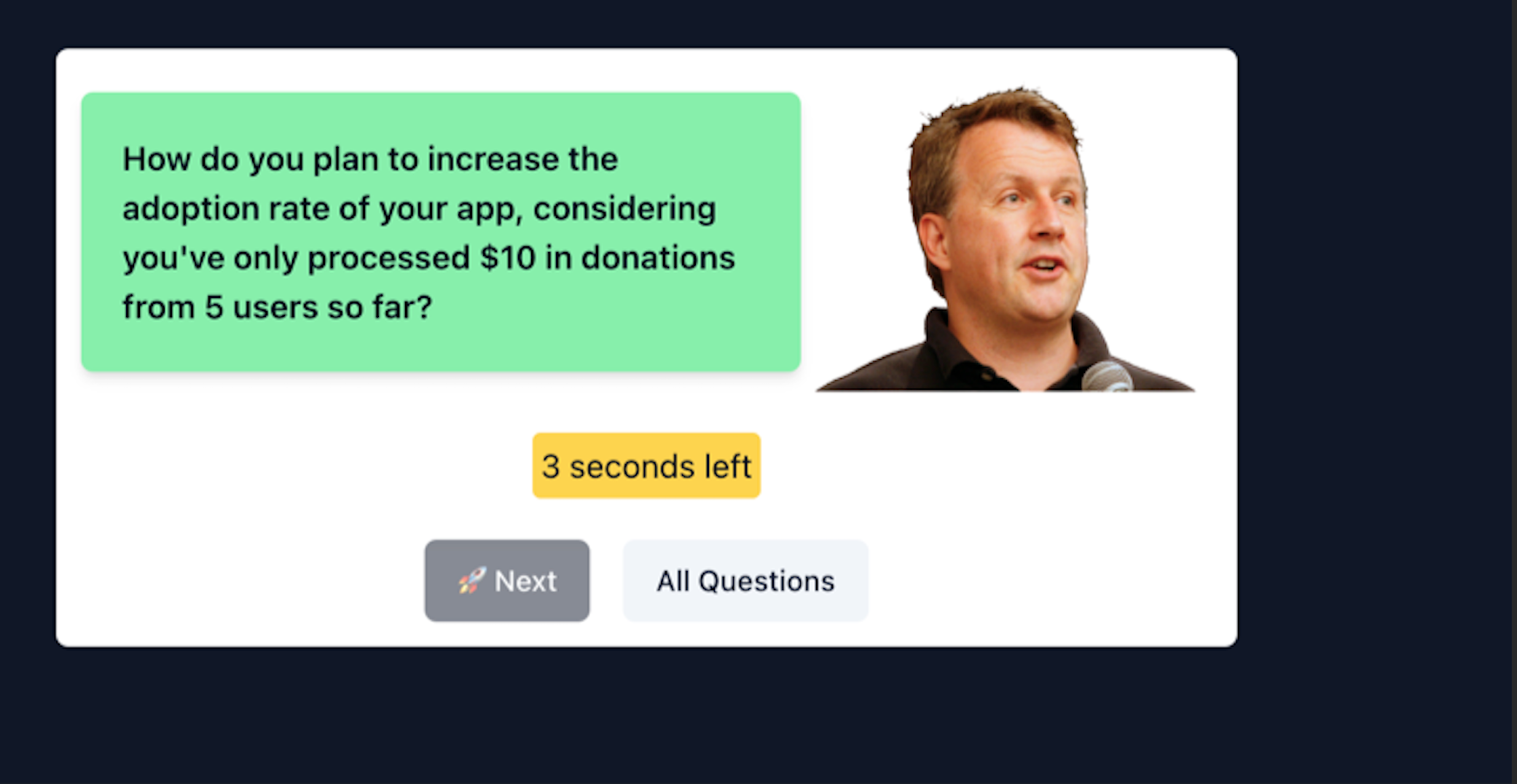
(fun fact - this is literally the first question we got asked in our YC interview! 😅)
We hope this helps! If you ever want to do a mock interview live, or have any questions your company (or even how we built this) - we'd love to chat! Feel free to reach out at founders@lytix.co.
How we deploy and monitor YC-Bot
Here's how Lytix helped us deploy and keep track of how YC-bot is performing in production
Minimizing costs
Because our pipeline includes several pretty heavy LLM calls, we wanted to be cognizant of how much money we'd spend per call. Since cost was our biggest priority, we used OptiModel to always choose the cheapest LLM provider (as opposed to the fastest, most reliable etc..). This helped us cut our LLM costs by ~1/3, while saving us the hassle of writing bespoke code for each provider we were considering.
response = await queryModel(
model=ModelTypes.llama_3_8b_instruct,
messages=[
ModelMessage(
role="system",
content="You are a helpful assistant.",
),
ModelMessage(role="user", content=prompt),
],
validator=validator,
fallbackModels=[ModelTypes.llama_3_70b_instruct],
temperature=0,
maxGenLen=2000,
)Error detection
Our primary goal for this project was to ask questions that were relevant to the users company and application. This made similarity to prompt an important metric for us to track. Similarity to prompt is an eval metric showing how semantically similar an output was to the provided context.
We configured a custom alert, to make Lytix-bot Slack us whenever it sees the model ask a question that was not similar enough to the provided context.
Thanks for reading!
You can learn more about how lytix can help you build, scale and iterate your LLM apps here. If you'd like to get some help with challenges specifically, or just chat about what you're building - feel free to grab some time here or reach out at founders@lytix.co!
👨💻
📣 If you are building with AI/LLMs, please check out our project lytix (opens in a new tab). It's a observability + evaluation platform for all the things that happen in your LLM.
📖 If you liked this, sign up for our newsletter below. You can check out our other posts here (opens in a new tab).