Easily configure guardrails and model chains with Optimodel v2!

Learnings from our v1
Earlier this year, my cofounder and I built the v1 of Optimodel, an open source project we hoped would help AI developers ship faster, focus more on product and less on tech debt. We were specifically focused on 2 problems:
- How could we minimize friction from switching from one foundational model to another?
- How can we help developers manage chains of multiple models, and easily choose which model is best suited for each task? (For ex. multimodal models for multimodal tasks, large context windows for large inputs, small models for speed)
For our first version, our hypothesis was that cost would be developers primary concern - “give me the cheapest model unless I say otherwise.”
After getting some feedback from HN, local developer meetups, and working with our own customers we noticed the following -
- Cost (on the micro, cost per token level) isn’t always the top concern. The majority of teams are still early, iterating fast and figuring out what PMF looks like. In that environment, most teams believe it’s better to build what your customers want first, track costs along the way and figure out expenses later.
- Developers were more interested in the broader capability of being able to easily call different models and conditioning on responses on the fly, than the specific use case of optimizing for ‘cheapest model’. We noticed teams using the pattern of “try model 1, check response, fall back on models xyz”
- to safeguard their model chains against known failures
- offset costs (on the macro, ‘workflow’ level) by being able to try cheaper models first, with the confidence that larger models were there if needed
- Teams were using custom business/product logic as filters, just as much as they were using generic filters like prompt injection, PII etc…. In this way, they were using Optimodel more to safeguard their overall LLM workflow, than to switch foundational models based on cost.
- For example - for a meeting summarizer, ensure each ‘action item’ has a due date (Datetime) and Assignee (email address), before passing everything off to the next model.
- Or - first try this smaller model, finetuned on our data. Check the output - if it’s ‘wrong’ then fallback to a larger model.
We wanted to iterate on this in Optimodels next version →
v2 ->
We streamlined Optimodel to focus on adding guardrails to inference calls and supporting multiple-model workflows.
- Adding guardrails to inference calls is now incredibly easy and configurable.
Lets take the example of PII (personally identifiable information i.e. names, email addresses, phone numbers). It’s common for developers to want to hide any of their users PII contained in the prompt, before making their inference calls, to minimize exposure to potential data leaks. Lets use Microsoft Presidio (an API designed to identify PII in strings) to guardrail our inference call, to ensure no PII is ever leaked.
Here’s a standard call to GPT 3.5 turbo, asking it to write a sales email to a product I’m working on.
import openai
# Define the prompt
prompt = "Write a short 3-5 sentence email to the manager of a marketing team about a new product. Please make sure to include my email sahil@fakeemail.com"
### Call the GPT-3.5 Turbo model
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": prompt}
],
max_tokens=256
)
# Extract and print the response content
response_content = response['choices'][0]['message']['content']
print(response_content)Here’s the response -
Subject: Exciting New Product Launch Details
Hi [Manager's Name],
I'm thrilled to introduce our latest product, [Product Name], set to launch on [Launch Date]. We believe this product will make a significant impact in [market/industry], and I would love to discuss our marketing strategies to maximize its launch. Please let me know a convenient time for a meeting.
Best regards,
Sahil
sahil@fakeemail.com
[Your Job Title]
[Your Company Name]The email copy is good, but you can see the end of the email contains my email address - not ok if I’m keen on not leaking any PII. Even if my user has asked me to include it, as the developer I should override this.
Let’s rework this code to call OpenAI via Optimodel. And we’ll use Optimodel’s new guardrails to handle this case. I’ll configure a custom message to be displayed if we see the user has included an email address.
prompt = "Write a short 3-5 setnence email to the manager of a marketing team about a new product. Please make sure to include my email sahil@fakeemail.com"
response = await queryModel(
model=ModelTypes.gpt_3_5_turbo_0125,
messages=[
ModelMessage(
role="system",
content="You are a helpful assistant. Always respond in JSON",
),
ModelMessage(role="user", content=prompt),
],
temperature=0,
maxGenLen=256,
# Lets also make sure we never leak any PII
guards=[
MicrosoftPresidioConfig(
guardName="MICROSOFT_PRESIDIO_GUARD",
guardType="postQuery",
entitiesToCheck=["EMAIL_ADDRESS"],
blockRequest=True,
blockRequestMessage="Sorry I'm not able to process queries with PII like emails",
),
],
fallbackModels=[ModelTypes.gpt_4],
)print(response)> {'modelResponse': "Sorry I'm not able to process queries with PII like emails", 'promptTokens': 45, 'generationTokens': 256, 'cost': 0.00016035, 'provider': 'openai', 'guardErrors': ['MICROSOFT_PRESIDIO_GUARD']}print(response.modelResponse)> "Sorry I'm not able to process queries with PII like emails"print(response.guardErrors)> ['MICROSOFT_PRESIDIO_GUARD']With just a few lines of code, we're not only able to block requests containing PII, but easily configure a relevant error message for the user (to use later in UX)
Adding guardrails with no-code
We also noticed that as teams scale, more and more non-technical members want to be able to make changes as well. That’s why we made it easy to add guardrails with no-code. Here’s how you can add the same PII guardrail without ever touching a line code.
You can see that by configuring the guard in the web app, we can comment out the guardrails in-code and still get the same behaviour.
Create and visualize workflows
Lastly, we wanted to help developers manage chains of multiple models. Which model should they use for each task? How can you quickly switch between models? And how can you visualize how multi-step chains performed?
We added a session_id to optimodel, letting users tie multiple inference calls into a single workflow.
To show this in action, let’s imagine a workflow that needs 2 LLM calls
- get a summary of a youtube video based on the URL
- lets assume the output has to be in JSON (so it can be passed to the next model)
- Generate a marketing email based on the contents of the video
- Lets assume we want no PII in the email
First, lets create the optimodel blocks for each component, adding guards/validators for each that makes sense. And to tie them both together, we’ll pass the same session_id to both blocks
# Boilerplate code to get video ids and transcripts from a youtube URL
def get_video_id(url):
"""Extract the video ID from a YouTube URL."""
query = urlparse(url)
if query.hostname == 'youtu.be': # handle youtu.be URLs
return query.path[1:]
if query.hostname in ('www.youtube.com', 'youtube.com'): # handle youtube.com URLs
if query.path == '/watch': # handle watch URLs
return parse_qs(query.query)['v'][0]
if query.path[:7] == '/embed/': # handle embed URLs
return query.path.split('/')[2]
if query.path[:3] == '/v/': # handle /v/ URLs
return query.path.split('/')[2]
return None
# Function to get the transcript of a YouTube video using its URL
def get_transcript(url):
video_id = get_video_id(url)
if not video_id:
return "Invalid YouTube URL"
try:
transcript = YouTubeTranscriptApi.get_transcript(video_id)
# Combine the transcript parts into a single string
transcript_text = ' '.join([entry['text'] for entry in transcript])
return transcript_text
except Exception as e:
return f"An error occurred: {str(e)}"
# make a session id up top
session_id = str(uuid.uuid4())Generating a summary from a transcript, guaranteeing the response is JSON -
def jsonValidator(toParse) -> bool:
try:
json.loads(toParse)
return True
except Exception as e:
return False
async def url_to_summary(url):
transcript = get_transcript(url)
if "An error occurred" in transcript or "Invalid YouTube URL" in transcript:
return transcript
summary_prompt = (
"You will get a transcript of a YouTube video. "
"Please summarise it into 5 points. "
"Please return the response in JSON in the following shape "
"{point_1: point1}, {point_2: point2}, {point_3: point3}, {point_4: point4}, {point_5: point5}. "
f"Transcript: {transcript}"
)
# url to summary
summary_response = await queryModel(
sessionId=session_id,
model=ModelTypes.gpt_3_5_turbo,
messages=[
ModelMessage(
role="system",
content="You are a helpful assistant. Always respond in JSON syntax.",
),
ModelMessage(role="user", content=summary_prompt),
],
# ensure response is JSON
validator=jsonValidator,
# fallback on bigger model if it's not
fallbackModels=[ModelTypes.gpt_4],
)
summary_json = summary_response['modelResponse'] # Extract only the modelResponse value
return summary_jsonand now, creating a marketing email based on a summary:
async def url_to_email(url):
summary = await url_to_summary(url)
email_prompt = (
"You wil get 5 points summarizing a video. Please use the summary to write an email marketing the product in the video. Please make it 3-5 sentences long. "
+ "Be sure to include my email sahil@fakeemail.com. "
+ " Summary: "
+ summary
)
email_copy_response = await queryModel(
sessionId=session_id,
model=ModelTypes.gpt_4,
# model=ModelTypes.gpt_3_5_turbo,
messages=[
ModelMessage(
role="system",
content="You are a helpful assistant.",
),
ModelMessage(role="user", content=email_prompt),
],
# add PII guardrail
guards=[
MicrosoftPresidioConfig(
guardName="MICROSOFT_PRESIDIO_GUARD",
guardType="postQuery",
entitiesToCheck=["EMAIL_ADDRESS"],
blockRequest=True,
blockRequestMessage="Please remove the email address and any personal identifiable information from your email prompt and try again. ",
),
],
)
email_copy = email_copy_response['modelResponse']
return email_copyBy creating a unique session_id for each session, I can track how a single request hit this 2 step workflow in lytix! I can use this to debug why sessions went wrong, track a users E2E flow in one place, and get analytics on each step.
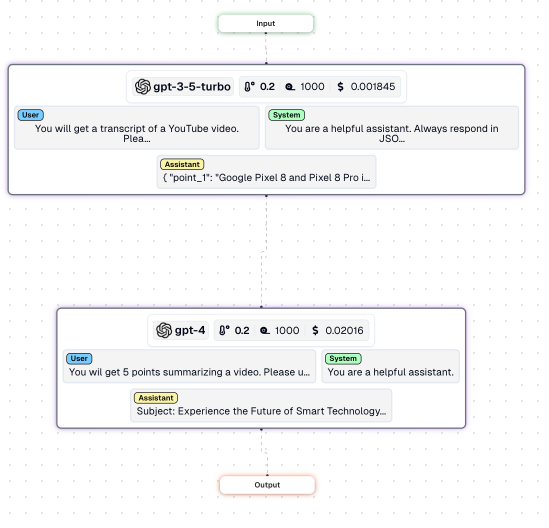
Here's how the workflow looks for the happy path -
And here's how it looks if your user hit a guardrail -
👨💻
📣 If you are building with AI/LLMs, please check out our project lytix (opens in a new tab). It's a observability + evaluation platform for all the things that happen in your LLM.
📖 If you liked this, sign up for our newsletter below. You can check out our other posts here (opens in a new tab).