Multimodal LLMs vs. Diffusion modals - what's the difference?

From an outside perspective, it feels like there’s basically no difference between multimodal LLMs and diffusion models. As a user, I use natural language to describe what image I’d like, and the model gives me an image based on my prompt. This is true for multimodal LLMs like GPT 4o and Gemini, and diffusion models like DALLE3.
https://x.com/gdb/status/1790869434174746805?s=46 (opens in a new tab)
But under the hood, these technologies are wildly different. In fact, some are even saying todays LLMs are “experiencing their Stable Diffusion moment”. Are LLMs that different from diffusion models? And if we already have diffusion models, why are multimodal LLMs such a big deal?
I wanted to explore exactly what made these technologies so different, and hopefully understand what makes mutlimodal LLMs so unique.
How they’re trained and where they come from
Diffusion models
A family of models (called score-based generative models), which specialize in creating high quality images, videos and audio. Stable diffusion (opens in a new tab), specifically, is a particularly effective diffusion model implementation released in August 2022.
Diffusion models use the following process to learn how to make new media (we’ll use an image as an example) -
1. Forward diffusion We start with an image, and add progressively more and more statistical noise to it. With each iteration, we add more and more noise and track how the image changes.
We repeat this until the image is entirely noise, losing all recognizable features.

https://www.calibraint.com/blog/beginners-guide-to-diffusion-models (opens in a new tab)
By tracking how different parts of the image change as more and more noise is added, the model learns a mapping from an image to its noisier counterpart at each step.
2. Reverse diffusion By teaching the model how an image degrades as more noise is added, we have inadvertently taught it how to create an image from statistical noise.
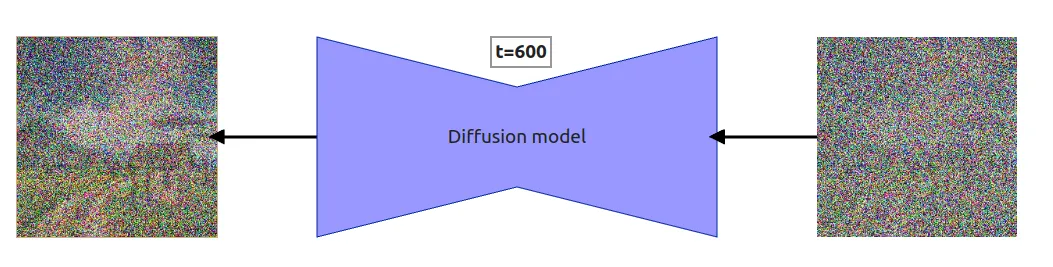
- Guided denoising This is how the model creates an image based on the users prompt.
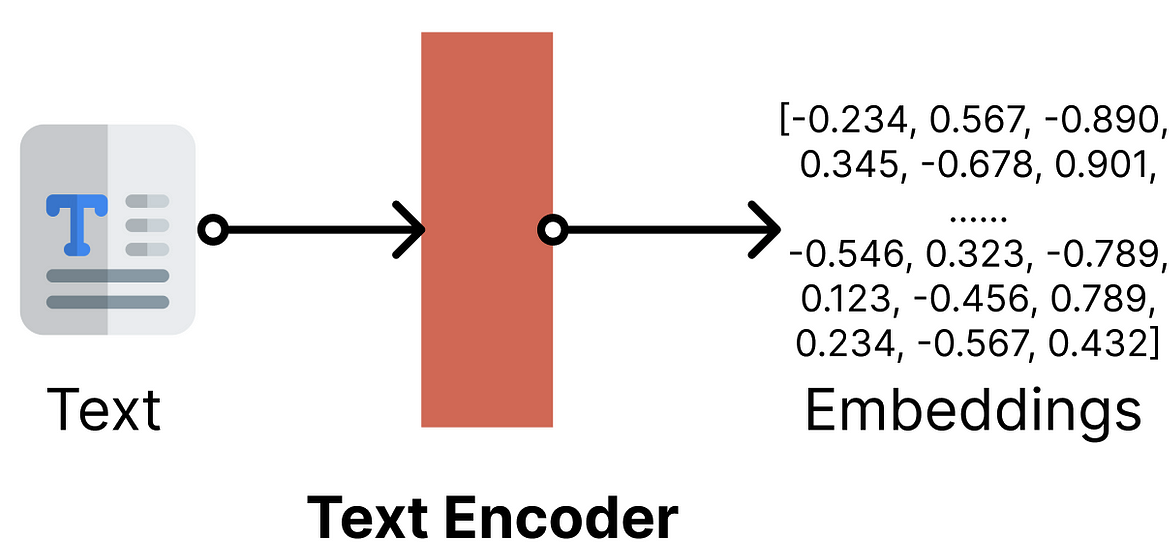
The users prompt is “embedded” into a vector, representing the prompt’s semantic meaning. This vector acts as a ‘guide’, steering the model towards what it thinks the user intended.
As the model iteratively ‘denoises’ random noise into an image, it compares the resulting image against the users prompt vector. The goal is to keep going, until the final image is as close as possible to the users prompt vector.
Multimodal LLMs (mLLMs)
Deep learning models built on the transformer architecture - a type of neural network developed in 2017.
Transformers are deep learning models that specialize in the following:
- “Sequence transduction” - or tasks that require turning an input sequence into an output sequence (via techniques called encoding/decoding)
-
Efficiency and Scalability - transformers can be run on huge amounts of data. This was critical for the development of LLMs, which are trained on huge huge amounts of data (OpenAI’s GPT3 was trained on 45 terabytes of data)
-
Strong understanding of the semantic meaning of strings - transformers have a few novel features (i.e. self-attention mechanisms) are great at identifying what a string really means, and encoding that into a vector that models can understand. They are better than previous models, would struggle with things like negations (i.e. please do not include a camel).
LLMs are made by training transformers on huge amounts of data. For ‘single modal’ (text-based) LLMs, this training teaches the model the relationships between different words. LLMs can use that skill to understand huge amounts of text, generate semantically accurate sentences, and predict what the next word in a string should be.
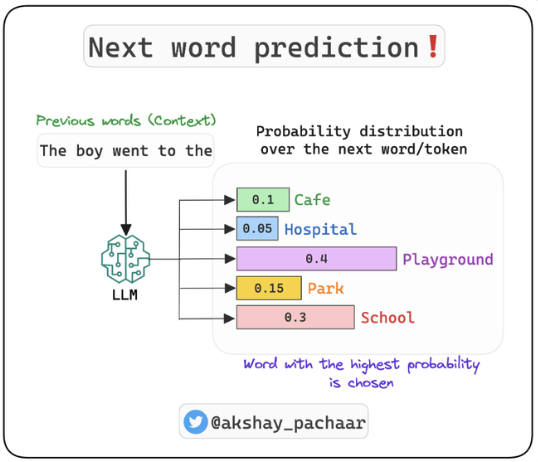
https://x.com/akshay_pachaar/status/1667147092614336512 (opens in a new tab)
This behaviour can be further extended (via finetuning) to accomplish specific tasks (i.e. follow along a conversation, answer user questions, follow instructions etc..)
Multimodal LLMs take this fundamental process, and extend it beyond just text data. Transformers are trained on not just text data, but labelled images, video and audio as well. This gives multi-modal LLMs the same understanding of patterns as single-modal LLMs, but across datatypes. (i.e. “duck” == 🦆)
Great - what does that mean in practice?
While it may seem like the end result is the same (write text, get image), these technical differences actually drop down into some meaningful differences in capabilities and features:
Creativity:
Diffusion models are by far better suited for creating assets that benefit from creativity - like company logos or artwork. There is much more ‘Stochasticity’ (fancy word - for randomness) in how diffusion models create outputs than LLMs. Diffusion models work by making random additions to ‘noise’, and progressively checking to get them closer and closer to the vectorized user prompt.
This means the variance in output of diffusion models is far greater than that of LLMs. LLMs are relatively bounded by patterns they’ve seen before (although there is a lot of room for variance within those patterns, and LLMs are by no means deterministic). Diffusion models, by contrast, are not bound by any previous associations between text, images and videos. They rely much more on the random ‘denoising’ of an image, using the vectorized user prompt as a ‘guide’. This lets more random elements enter the diffusion models image, than the mulimodal LLMs image.
For example, we asked a multimodal LLM and a stable diffusion model to create a logo for a fictional soda company.
Here’s the multimodal LLMs response (GPT 4o) -

And here’s the diffusion model’s response -

You can tell that the LLMs response is more directly drawn from previous patterns (even literally including “Coca Cola” in the image 🤔). The diffusion model’s image is also generally more vibrant and rich than the LLMs (which feels to me more “flat” and cartoonish in comparison).
Quality of media generated
“Iterative denoising” as a technique for image generation, is especially good at creating high resolution, detailed images. The forward diffusion process gives diffusion models incredibly fine control over what parts of an image can be edited and how. And iterative denoising lets diffusion models use that fine control, to add more and more details and controls to the final image. While mutlimodal LLMs can create images with a lot of detail, a diffusion model would create the same level of detailed with less compute and more reliably.
prompt - make an image of a monkey drinking coffee
The Multimodal LLM -
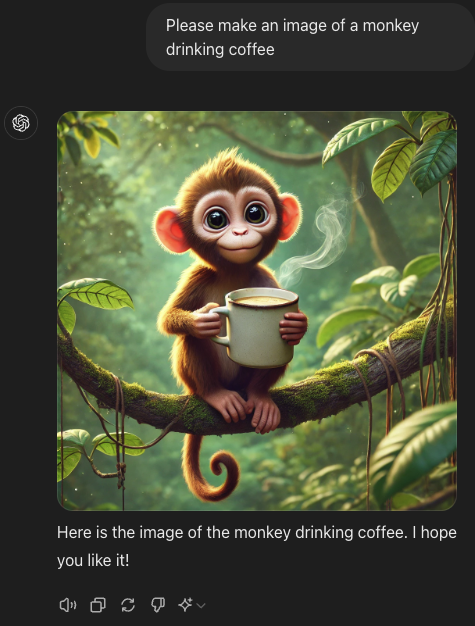
vs. the Stable Diffusion model
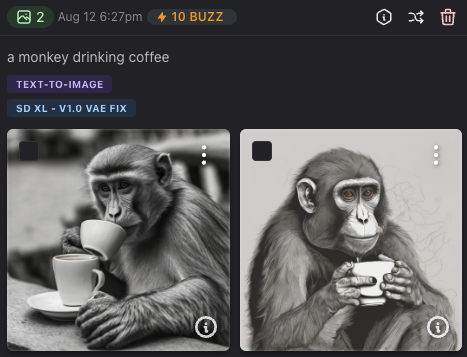
The stable diffusions images are more realistic than the mLLMs response.
Understanding of Prompt
Diffusion models are not as well suited for understanding the data that’s passed to it, as LLMs are. What does that mean?
- A multimodal LLM would be able to receive an image or video as a prompt, and ‘understand’ it’s contents. Today, diffusion models typically only produce images or video. You couldn’t pass a diffusion model a video, and use that as an input (for ex. as a reference).
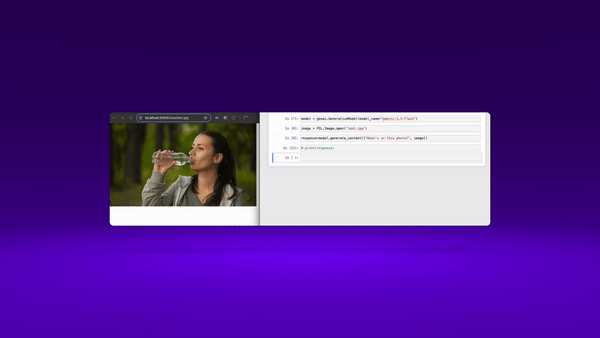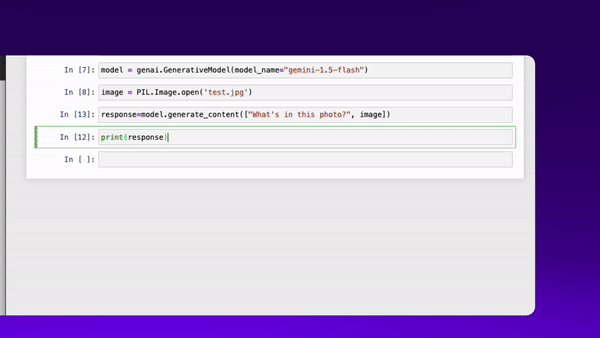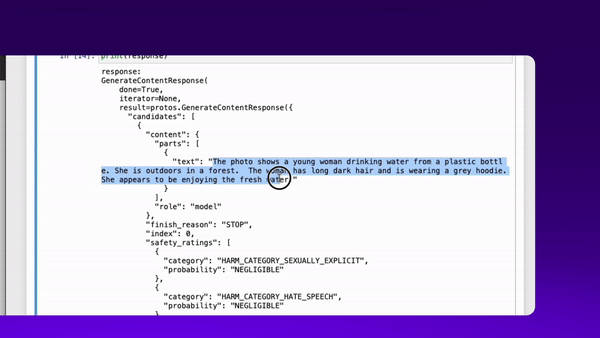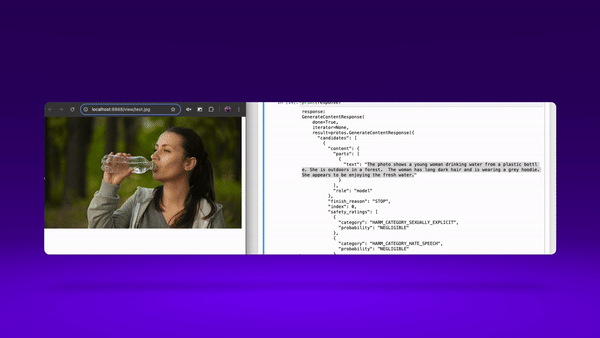
demo - multimodal LLM image inference in action
- The transformer architecture lets LLMs do a way better job of actually understanding the users prompt, than diffusion models are able to
A great example to show this - ask a diffusion model to make an image and ask it NOT to include a camel. It will definitely include a camel.
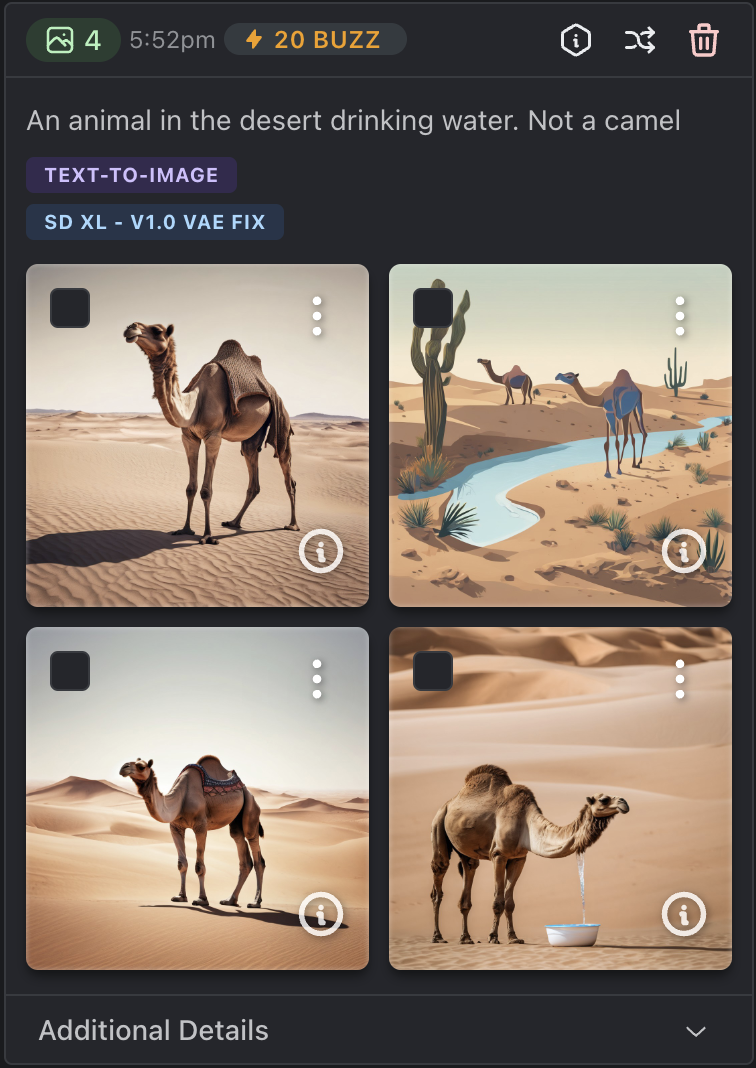
You can see that the model hasn’t done a great job of understanding what I actually meant in the prompt. It caught the ‘camel’ string in the prompt, and used that to guide image generation, without capturing the overall context. While the image is super clear, realistic and high quality, it’s missing a true understanding of what i asked for. Compared with asking a multimodal LLM -

Not only has the LLM understood what the prompt was actually asking for, but combined responded with the image and text of a non-camel desert (fennec fox).
This isn’t to say that one technique is inherently better than the other. Certain use cases will require the realism, detail and creativity from diffusion models (creating creative assets, music generation etc…). As AI starts to tackle more creative, media-rich spaces, these assets make diffusion models very powerful.
Multimodal LLMs may be better suited for use cases where more ‘familiar’ creativity is helpful, less range per output and more directly drawn from previous patterns. Additionally, mulimodal LLMs would be more useful for cases where capturing 100% of the user’s prompt (including negations, examples, references) is critical.
mLLMs also provide a wider funnel of inference for input - letting a model ‘understand’ images or videos. This can be used to ask a model to generate media similar to a ‘reference’ that is passed in.
Overall
This exercise was incredibly useful for me to understand why we should be paying attention to multimodal LLMs. The ability to generate media based on an input, and have the variance of that media be more controllable, is a huge new capability for AI developers.
I’m also understanding why the future of AI isn’t simply ‘one big model’. The way each family of models is trained carries inherent strengths and weaknesses for different use cases. I’m incredibly intrigued by how product teams will elegantly combine these different capabilities moving forward, to solve a new host of previously impossible to solve problems.
👨💻
📣 If you are building with AI/LLMs, please check out our project lytix (opens in a new tab). It's a observability + evaluation platform for all the things that happen in your LLM.
📖 If you liked this, sign up for our newsletter below. You can check out our other posts here (opens in a new tab).