Building + Evals for Multi-Agent Systems (Insired by Swarm by OpenAI)

A few weeks ago, OpenAI dropped Swarm - a framework for setting up and managing ‘multi agent’ systems. In 3 weeks it’s racked up over 15k stars on GitHub, been discussed to pieces on HN - with some developers even making some durable spinoffs of the library. Clearly there’s interest in the problems it’s solving!

Quick context: What is a “Multi-Agent System?”. A “multi-agent system” is one where a user may interact with multiple AI-powered agents. Each agent may have a specific focus, and be given access to functions/databases to power that function. For a given user query, the system needs to both choose the right agent for the query, and execute against that query perfectly.
For example, consider an e-commerce chat bot. It has to handle both handle new product inquiries (i.e. assist with product discovery, or process purchases) as well as questions about existing orders (i.e. delivery time, or help refunds/exchanges). If a user asks “Tell me about the new iPhone’s memory”, the “New Product” agent should be called. This agent may be connected to a vector database containing the company’s product information. It may also be given access to functions that let it process purchases.
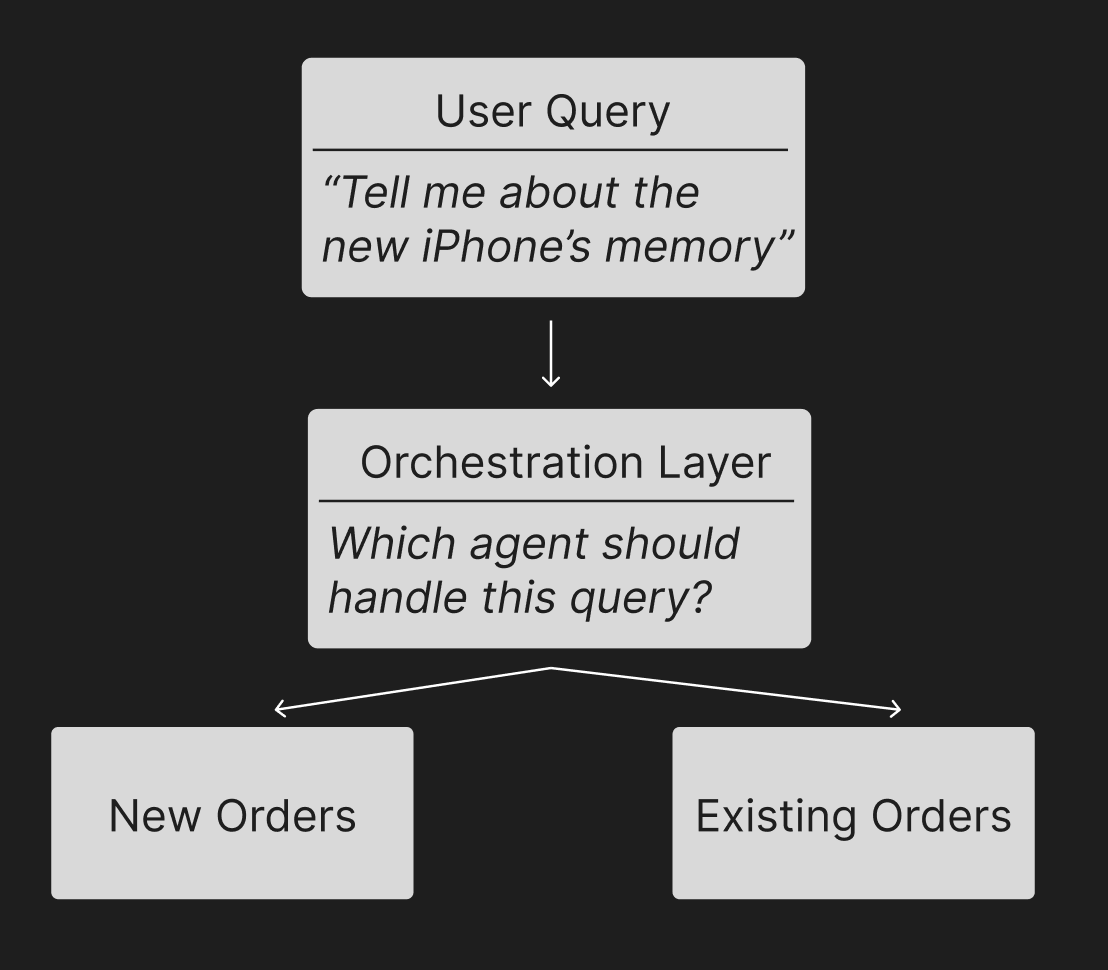
I was initially interested in Swarm because it touches on problems we hear a lot from our customers building multi-agent systems in the real world. We’ve heard how the many moving pieces and multi-variate analysis can quickly feel overwhelming. Not only do you have to build several robust agents, potentially with vastly different requirements (i.e. RAG workflows for one vs. back and forth conversing for another). But in addition, you need to build the orchestration layer that passes the user to the right agent. Without an analytical approach, observing and iterating on these systems can quickly get out of hand. Given all the traction Swarm has seen in such a short amount of time, it looks like many have felt these pains.

While Swarm (and the best practices it’s built on) definitely ease the developer experience of initially building these multi-agent frameworks, it doesn’t touch on the challenges of managing them over the long term. Specifically, how one should think about observability and iterations. In this blog post, I wanted to demo my quick exploration with Swarm and OpenAI’s handoff best practices, and how I’d think about evaluations, analytics and iterations, to continuously improve these systems over time.
In this blog post I:
- Built a POC with the Swarm agent - an e-commerce chatbot that can handle questions about new products and existing orders.
- Re-built it using OpenAI’s native client using their Agent Handoff best practices
- Run through a framework for evals and analytics, that I can use to catch breaks, validate + measure improvements to my system and iterate long-term.
Building my PoC in Swarm
Jumping into the Swarm docs for the first time, my first learning was that Swarm was never meant to be a durable system! Rather a proof of concept for OpenAI’s best practices for agent-handoffs.

(I wonder given all the recent traction, the clear need for a disclaimer and the copycats on HN - if OpenAI will feel differently about this being just an experiment, in their next few releases 🤔 Remember, ChatGPT was also initially released as a throwaway experiment!)
Here’s how I built my first multi-agent system, with the example output.
# Example code block in markdown
import os
from openai import OpenAI
from dotenv import load_dotenv # You'll need to install python-dotenv
from swarm import Swarm, Agent
# Load environment variables
load_dotenv()
# Initialize the client using environment variable
client = OpenAI(api_key=os.getenv('OPENAI_API_KEY'))
def get_completion(prompt: str) -> str:
try:
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": prompt}
]
)
return response.choices[0].message.content
except Exception as e:
return f"An error occurred: {str(e)}"
swarm_client = Swarm()
def transfer_to_agent_b():
return agent_b
def transfer_to_agent_a():
return agent_a
def transfer_to_handoff_agent():
return handoff_agent
# Handoff agent definition
handoff_agent = Agent(
name="Handoff Agent",
instructions="""You are the initial point of contact for an e-commerce store's customer service.
Your only job is to analyze the customer's question and transfer them to the appropriate agent:
- For questions about new products, purchasing, or product information: Transfer to New Product Agent
- For questions about existing orders, delivery times, returns, exchanges, or refunds: Transfer to Existing Order Agent
Before transferring, always say 'I'll transfer you to our [Agent Name] who can better assist you with this.'""",
functions=[transfer_to_agent_a, transfer_to_agent_b],
)
agent_a = Agent(
name="New Product Agent",
instructions="You are a helpful assistant for an e-commerce store. You are one of 2 agents that are working together to help the user. You are responsible for answering questions about new products. Your priority is to answer questions about new products, and drive purchases. If you answer questions well, customers will be more likely to buy products from the store. If you see a question about an existing order, you should transfer the question to Existing Order Agent.",
functions=[transfer_to_agent_b, transfer_to_handoff_agent],
)
agent_b = Agent(
name="Existing Order Agent",
instructions="You are a helpful assistant for an e-commerce store. You are one of 2 agents that are working together to help the user. You are responsible for answering questions about a customers existing order. This could be answering questions about delivery times, handling returns/exchanges, and processing refund requests. If you handle customers quickly, they will be more likely to purchase again. If a customer is not asking about an existing order, and they want information about new products, you should transfer the question to the 'New Product Agent'",
functions=[transfer_to_agent_a, transfer_to_handoff_agent],
)
# Example usage
if __name__ == "__main__":
swarm_response = swarm_client.run(
agent=handoff_agent,
messages=[{"role": "user", "content": "I ordered something but it doesn't fit right. And I've worn it once. What's the policy?"}],)
# print(client_result)
for message in swarm_response.messages:
if message.get('content'): # Only print if content exists and is not None
print(message['content'])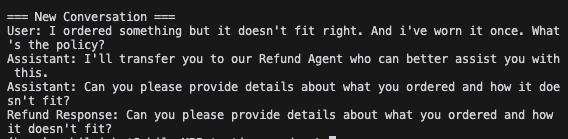
Perfect! My handoff agent correctly transferred my request to the “Refund” agent, who then responded appropriately.
Rebuilding with OpenAI (this time with observability)
Now that I had what I wanted, I quickly rebuilt it using OpenAI’s native client and their handoff best practices (shoutout cursor for making this quick 🙌). Here’s the updated code -
from openai import OpenAI
from pydantic import BaseModel
from typing import Optional
import json
import os
client = OpenAI(
# Update your base url to the lytix proxy
base_url=f"https://api.lytix.co/proxy/v1/openai",
# Update your api key to the lytix api key
api_key=<YOUR OPENAI API KEY>,
default_headers={
# Move your openai key to the default headers
"openaiKey": os.getenv('OPENAI_API_KEY')
},
)
class Agent(BaseModel):
name: str = "Agent"
model: str = "gpt-4o-mini"
instructions: str = "You are a helpful Agent"
tools: list = []
# Customer Service Routine
# Define the handoff agent's system message
handoff_system_message = (
"You are the initial contact agent for ACME Inc. "
"Your only job is to direct customers to the right department: \n"
"1. For new orders and product inquiries: Transfer to Sales Assistant\n"
"2. For refunds and order issues: Transfer to Refund Agent\n"
"Always say 'I'll transfer you to our [Agent Name] who can better assist you with this.'"
)
# Define the sales system message
sales_system_message = (
"You are a sales assistant for ACME Inc. "
"Help customers with new orders and product information. "
"Always answer in a sentence or less. "
"If customer mentions refunds or order issues, inform them you'll transfer them to the Refund Agent."
)
# Define the refund system message
refund_system_message = (
"You are a customer support agent for ACME Inc. "
"Always answer in a sentence or less. "
"Follow the following routine with the user:"
"1. First, ask probing questions and understand the user's problem deeper.\n"
" - unless the user has already provided a reason.\n"
"2. Propose a fix (make one up).\n"
"3. ONLY if not satisfied, offer a refund.\n"
"4. If accepted, search for the ID and then execute refund."
)
handoff_agent = Agent(
name="Handoff Agent",
instructions="You are the initial contact agent. Direct users to the appropriate department.",
)
refund_agent = Agent(
name="Refund Agent",
instructions="You are a refund agent. Help the user with refunds."
)
sales_assistant = Agent(
name="Sales Assistant",
instructions="You are a sales assistant. Sell the user a product.",
)
def run_full_turn(system_message, messages):
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "system", "content": system_message}] + messages,
extra_headers={
"workflowName": "ecommerce-bot",
},
)
message = response.choices[0].message
messages.append(message)
if message.content: print("Assistant:", message.content)
return message
if __name__ == "__main__":
messages = []
user_query = "I ordered something but it doesn't fit right. And i've worn it once. What's the policy?"
print("\n=== New Conversation ===")
print("User:", user_query)
messages.append({"role": "user", "content": user_query})
# Start with handoff agent
handoff_response = run_full_turn(handoff_system_message, messages)
# Based on handoff agent's decision, continue with appropriate agent
if "Sales Assistant" in handoff_response.content:
# Create new conversation with sales context
sales_messages = [
{"role": "user", "content": user_query}
]
sales_response = run_full_turn(sales_system_message, sales_messages)
print(f"Sales Response: {sales_response.content}")
elif "Refund Agent" in handoff_response.content:
refund_messages = [
{"role": "user", "content": user_query}
]
refund_response = run_full_turn(refund_system_message, refund_messages)
print(f"Refund Response: {refund_response.content}")
(Note: OpenAI’s docs also gives guidance for adding function calling (i.e. to actually process purchases). That felt out of scope for this MVP (plus tracking for those functions feels relatively solved), so I didn’t pull any of that code in.)

Great, now I can see both calls in my dashboard - the handoff agent transferring me to my refund agent, and the refund agents response 👍
Evals + Analytics
Next, how would I think about evals for these systems? These evals need to help me catch critical workflow errors, but also set up me up for long-term improvements. First, you’ll need to integrate your observability tool of choice. As you can see with the native code, I’m passing OpenAI requests via lytix (Spoiler alert, I am one of the founders of lytix so I am biased! But, we did build it for customers building multi-agent systems that are live and in-production. You’re more than welcome to use any observability/eval tool that works for you! Anything with model input/output events and prompt-optimized custom evaluations)
Broadly speaking multi-agent systems need 2 levels of evaluation:
- Who? i.e. For a given query, was the right agent called?
- What? i.e. Once called, did the agent perform it’s task correctly?
For 'For a given query, was the right agent called?', I find that LLM as Judge is a great approach, especially as you’re getting started and have limited data on what your users questions look like. While you could ultimately get fancy with regex and/or semantic scoring here, LLMs are great for classification/natural language tasks, letting you stay flexible and iterate faster.
Here’s a custom eval I set up using lytix, to evaluate if the right agent was called given the users query. I added some examples of good classifications for each, to take advantage of the benefits of K-Shot prompting.
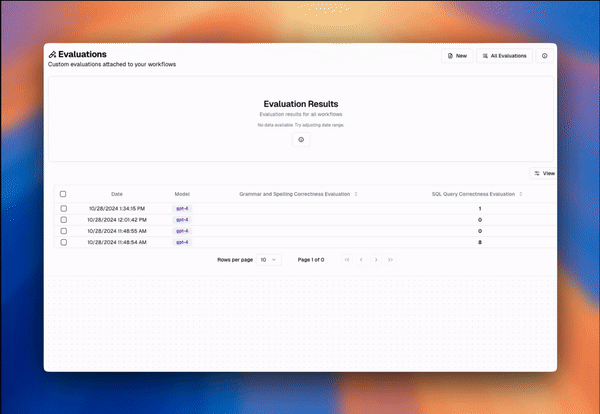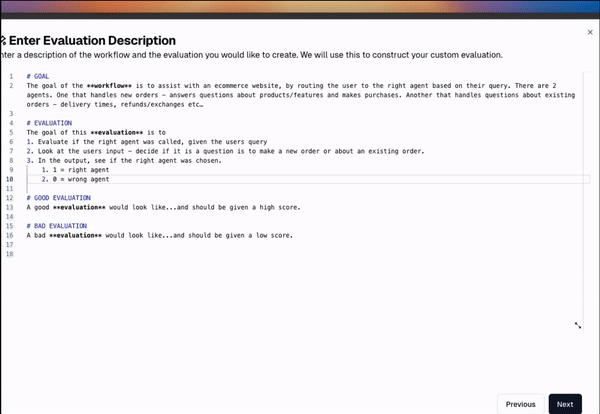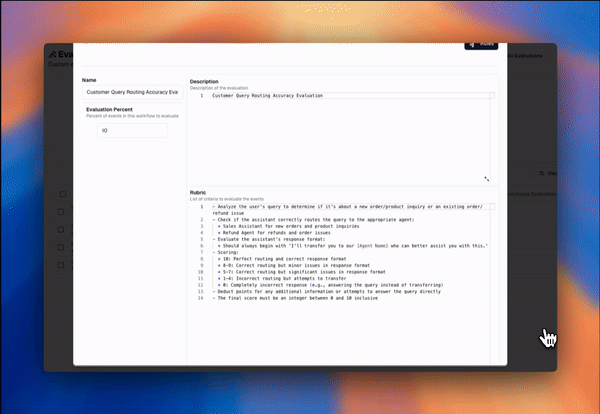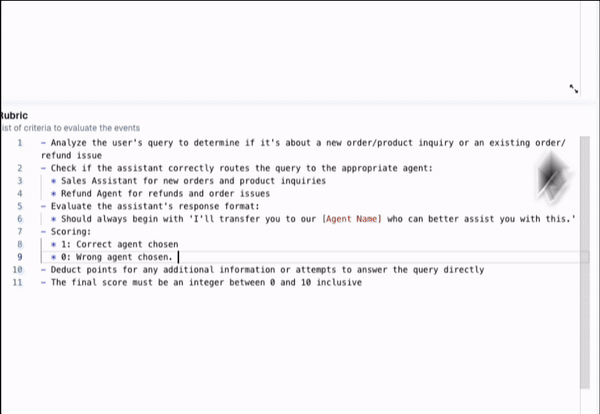 (Note: Lytix will build a ‘prompt-engineer optimized prompt’, using my descriptions and rubruc under the hood. It is important to employ prompt-engineer best practices on your evaluation models, as your eval results will only be as good as the model (i.e. prompt) itself. If you’re not using a tool like lytix that optimizes that under the hood, make sure to spend a second prompt-engineering your eval prompts).
(Note: Lytix will build a ‘prompt-engineer optimized prompt’, using my descriptions and rubruc under the hood. It is important to employ prompt-engineer best practices on your evaluation models, as your eval results will only be as good as the model (i.e. prompt) itself. If you’re not using a tool like lytix that optimizes that under the hood, make sure to spend a second prompt-engineering your eval prompts).
If I’m seeing instances of the wrong agent being called, then I can update my ‘handoff agent’ accordingly. For example -
- Edit the K-Shot prompt to include the user-prompt that confused the handoff agent, along with the correct agent it should have been transferred to
- Experiment with a different foundational model (i.e. one that has more reasoning)
- See if I need new agents to handle requests that may not fit cleanly for any existing agents
For if the agents themselves are performing correctly, the set of evals will depend on the function itself. I’d have anywhere from 1-3 evals running per agent, and evaluate each agent a as a separate product. It’s not uncommon to have multiple evals running per agent, evaluating different dimensions of the output or using different methods (i.e. LLM as judge’, off the shelf evals like RAGAs, or in-product conversion rates).
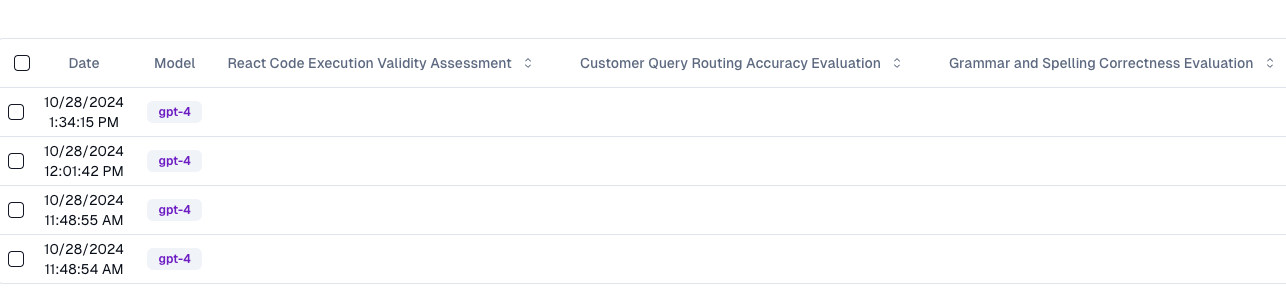 You’d want some table like this, that then lets you track multiple evals against the agent actions.
You’d want some table like this, that then lets you track multiple evals against the agent actions.
For agents that are primarily text-based (i.e. chat bots answering questions/returning information, vs. driving a specific conversion event i.e. a purchase), LLM as Judge models are great starts.
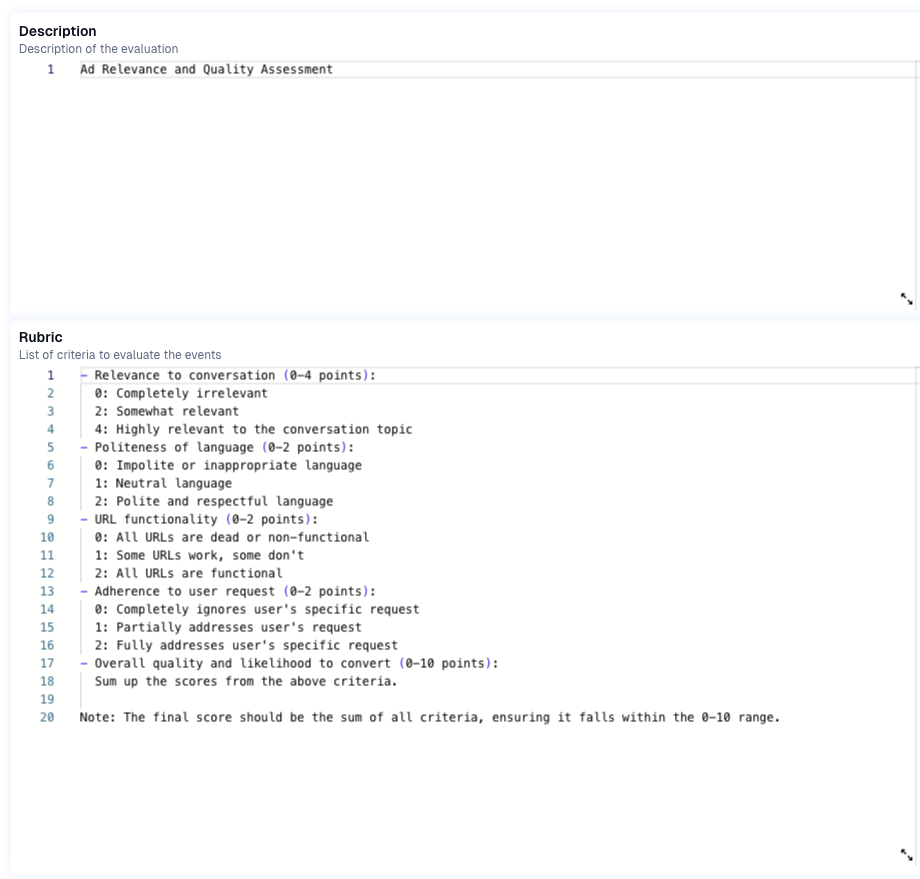 example - evaluates if an LLM-served ad was relevant to the previous conversation.
example - evaluates if an LLM-served ad was relevant to the previous conversation.
For agents that ultimately have to drive some end-conversion event in product (such as tapping a purchase button or filling out a form), I would definitely track your “LLM session → Conversion event” funnel. While you can supplement that with evaluating qualitative components (i.e. tone, did the bot answer the users question etc…), I think it’s critical for the north-star to be the actual conversion event. This will help you identify opportunities that really matter, and validate the impact of any changes you make.
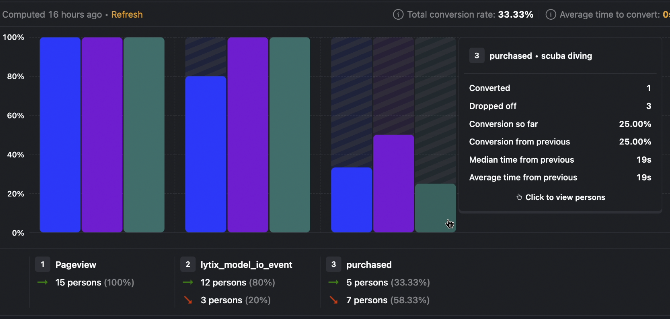 example - a chatbot that has to drive conversions. Here I’ve made a funnel of ‘how many users purchase after interacting with my lytix event’ (broken out by subject matter, i.e. what they’re talking to the bot about).
example - a chatbot that has to drive conversions. Here I’ve made a funnel of ‘how many users purchase after interacting with my lytix event’ (broken out by subject matter, i.e. what they’re talking to the bot about).
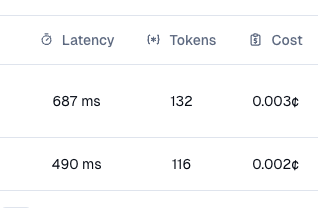
If you’re using RAG, evals like RAGAs will be critical tracking to ensure your bots are using your source of truth correctly. “Cost-per-run” of your workflows will also be important, as RAG can rapidly increase your input tokens and therefore cost. You’ll want to track both, so you can provide a great user experience, while having a handle on cost.
I hope this is a good analytical start for anyone hoping to set up a multi-agent systems. Would love to get feedback from anyone who’s tried this approach live! Always looking to improve it.
© lytix