Evals by use case - text to sql to insights
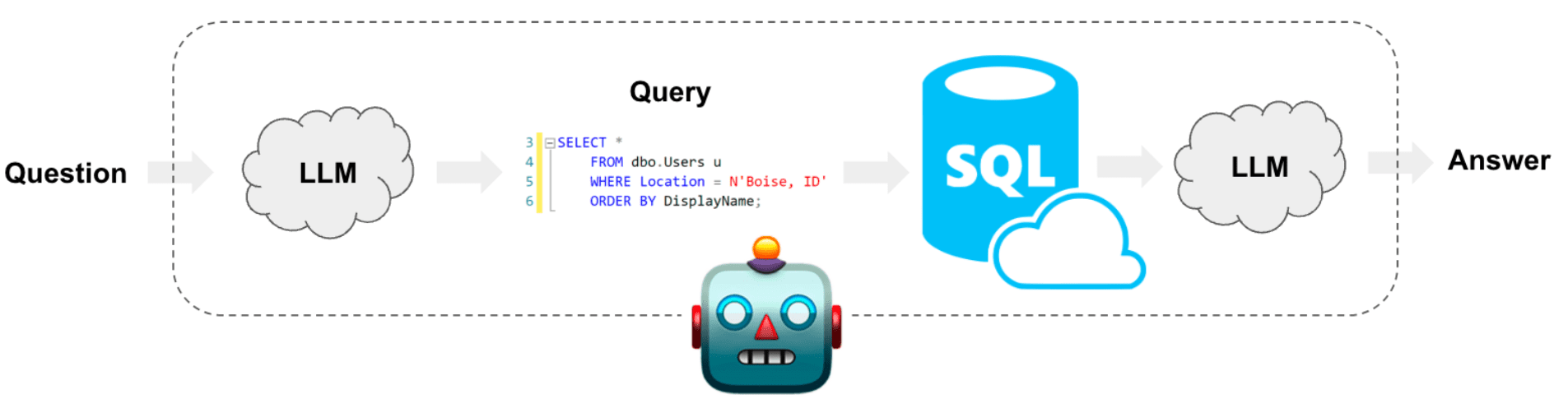
One of the early use cases of LLMs we were excited about was letting users interact with databases via natural language. This could be a small business inquiring about their operations or an internal employee querying their company's data warehouse. For example, there are thousands of "text to SQL" models on HuggingFace (opens in a new tab), with some models boasting over 100,000 downloads. It's evident that LLMs can be easily trained to write SQL, and there's a clear demand for this use case.
Having experimented with several of these models and worked on multiple "text to insights" projects with our customers at lytix, I've identified a couple of common points of failure and how to address them.
Problem 1: The right SQL
The first challenge with using LLMs for ‘text to sql’, is getting the agent to produce the right SQL for your warehouse. Anyone who’s worked with data in the real world knows that everyone’s data warehouse is different. There’s typically a ton of tribal knowledge required to produce the right SQL to answer a given question. Names of columns and tables, how tables are related to each other, the right filters to apply.
This problem becomes immediately apparent as soon as you start playing with the ‘text to sql’ finetuned models on HuggingFace. The SQL is always great in theory, but usually far from the right query to answer the question given how your data is stored.
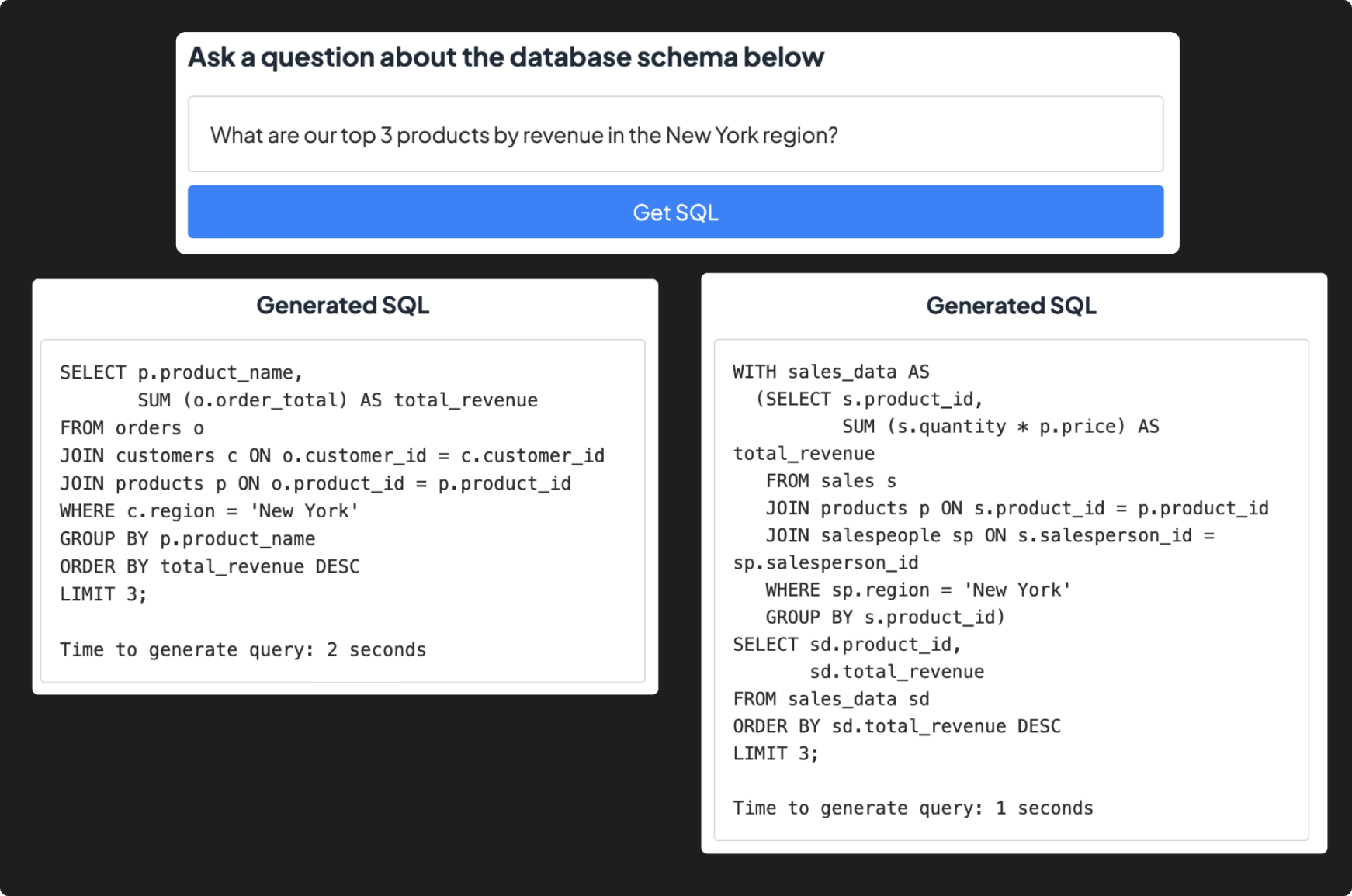 Example - two different SQL queries for the same question, based on different assumptions of how the data is stored.
Example - two different SQL queries for the same question, based on different assumptions of how the data is stored.
The solution? Prompt engineering and evaluations.
Prompt engineering
Your first task is to tell your model how your data is stored. This sounds simple enough in theory, but there’s definitely a balance to be struck.
First, any analyst knows that it’s surprisingly hard to document all the details of how a data warehouse is built. Let alone concisely and clearly enough to explain to a model. It’s unlikely that in first try, you’ll include all the details necessary to cover your users queries. But, with the right evaluations, you’ll be able to iterate your way there quickly.
Secondly, adding more detail will increase your input tokens, increasing the cost and latency of each call. The result is an expensive system and a slow user experience. You’ll want to strike a balance between including just enough to cover the majority of your users queries, and not bogging your system with an over-stuffed context window.
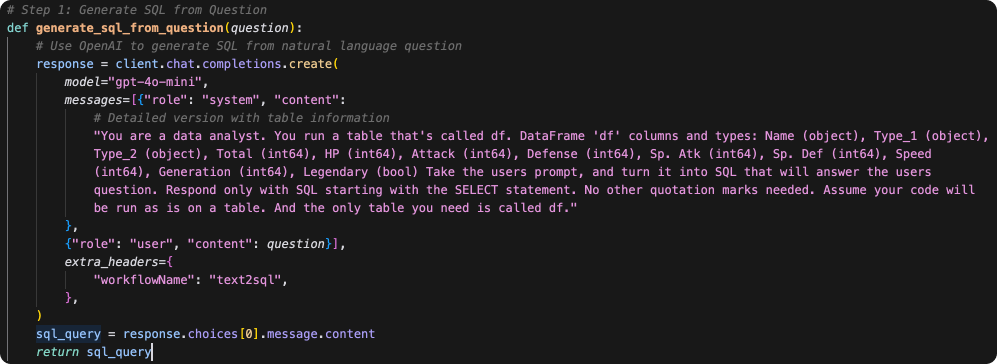 Example - including some necessary schema details to help the model produce the right SQL.
Example - including some necessary schema details to help the model produce the right SQL.
Evaluations
I think it makes sense to have one evaluator agent, monitoring only if the SQL produced is valid given your architecture. You can use this to play with the amount of details you give your model, and iterate based on the % of questions it’s able to produce valid queries for, vs. how expensive and slow each inference call is.
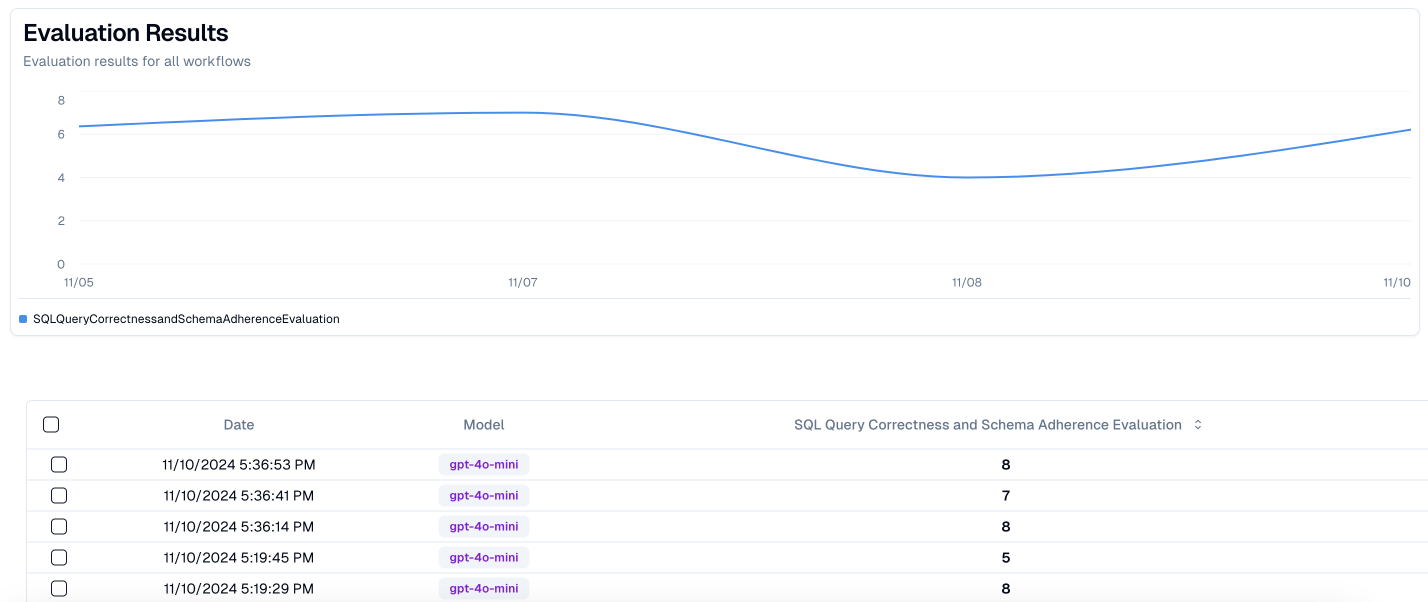 Example - using an evaluator agent to monitor the % of queries that are valid.
Example - using an evaluator agent to monitor the % of queries that are valid.
Problem 2: the question
I’ve also noticed that often times the users original query is too vague, or lacks critical detail needed to fully answer the question. The direct ‘text to sql’ models won’t consider this, and confidently produce SQL based on the question they’re asked.
It may make sense for your system to have a primary agent that considers the users question, and determines if any additional details are required. For example, in the question - “what are my best performing SKUs?”, it may make sense to have an agent confirm what “best” means (most revenue, most margins, most volume?), and then handing a more direct, fully query to the SQL agent.
As an example, here are three different ways of asking the same question, and the SQL that results from each.
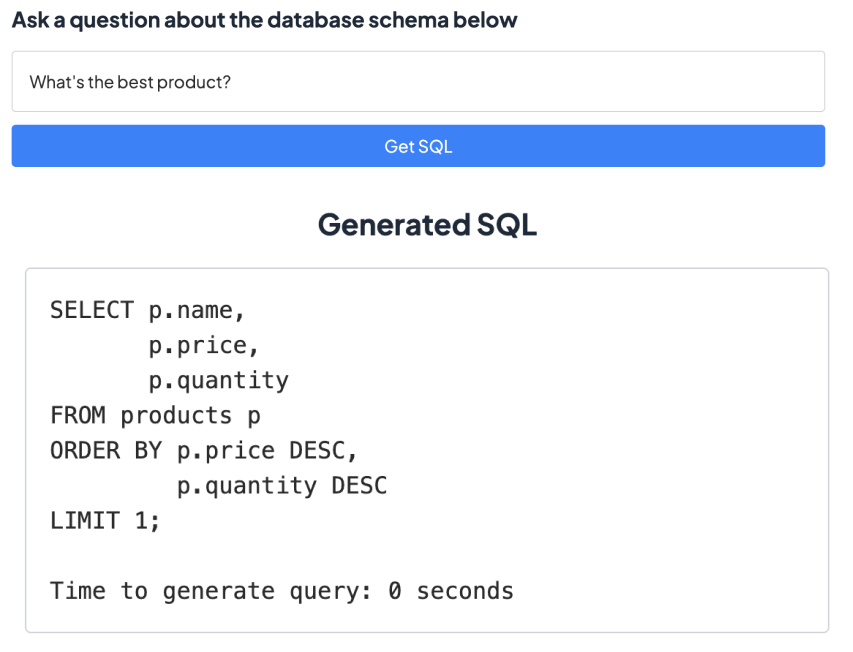
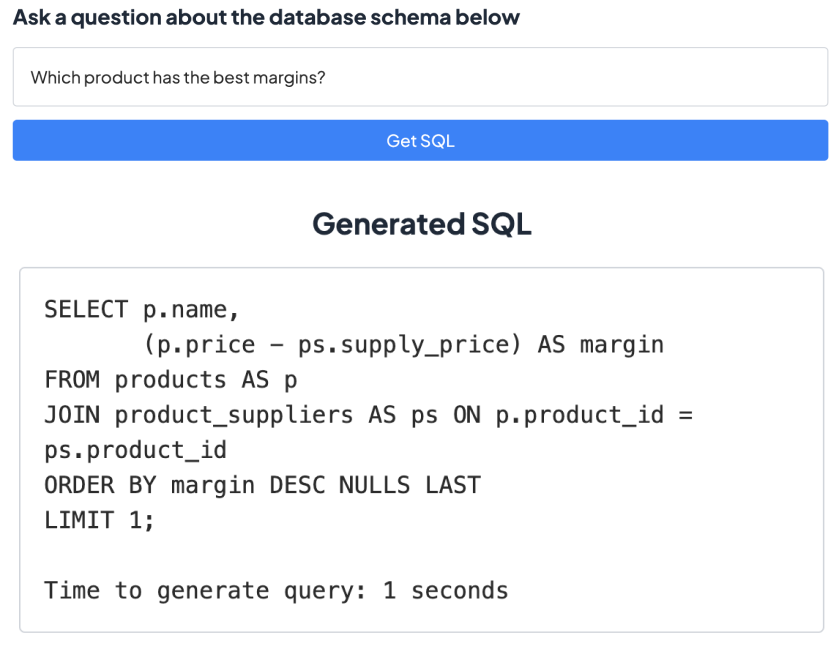
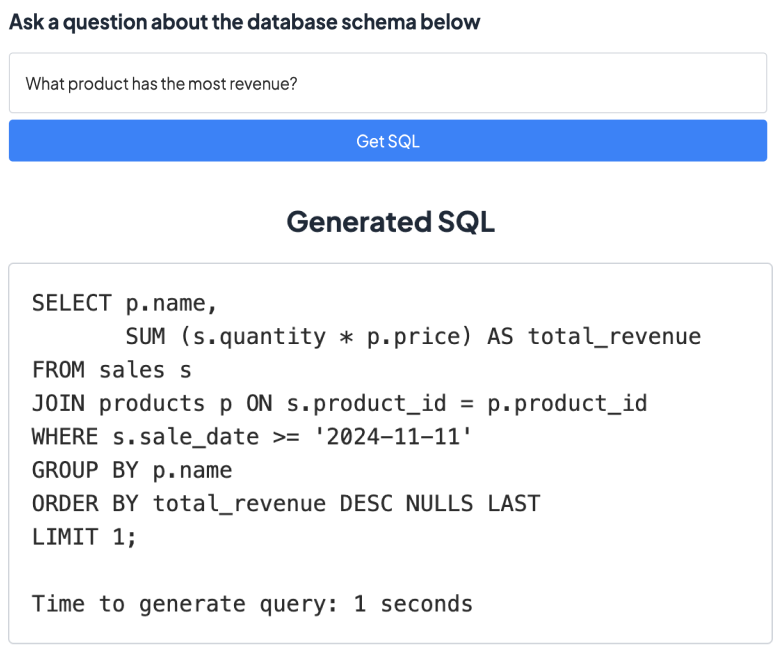 Example - different SQL queries for the same question, based on different assumptions of how the data is stored.
Example - different SQL queries for the same question, based on different assumptions of how the data is stored.
You’ll want to give the agent as much context as to what details may be necessary. You’ll also want to have this agent readily available, as you may not get the answer right on the first shot. In reality, the process of getting to the right query is highly iterative. I’d engineer your system assuming that it will be routinely re-called, to iterate on the last query based on feedback.
Evaluations
I think a few layers of evaluation make sense for this piece.
- How often is SQL re-generated? How often is the agent called? That’s a good approximation for the query clearly needing some refinement.
- I’d look at what kinds of queries are frequently getting re-generated, and add details accordingly. When you add a detail, I’d confirm that your average “SQL-generated per session” is going down
- Another eval could be how often prompts with ‘ambiguous’ words are intercepted by your agent. You could look for specific words like REGEX, or use models like BLEU and ROUGE to find words that are similar to a corpus of known ‘troublemaker’ words. You’ll want to confirm how many prompts containing problematically ambiguous language (tracked via REGEX or BLEU/ROUGE).
- Finally, you could harness the power of LLMs and whip up an LLM as Judge eval. The pros are that you can have it apply some reasoning, and do a more holistic/realistic evaluation of a session. The cons are that they’re slower and more expensive than the other types of evaluations. At lytix, we recommend people run more complex LLM as Judge evals on up to 25% of events in a workflow.
Problem 3: Security
When implementing LLMs to query data, security is paramount. There are two main security risks to consider:
- Prompt injection attacks: Malicious users might attempt to craft prompts that trick the LLM into revealing sensitive or private information. To mitigate this, it's crucial to implement strict input validation and sanitization.

- SQL injection attacks: If not properly secured, the generated SQL queries could be manipulated to perform unauthorized actions on the database. This risk emphasizes the need for thorough query validation before execution.
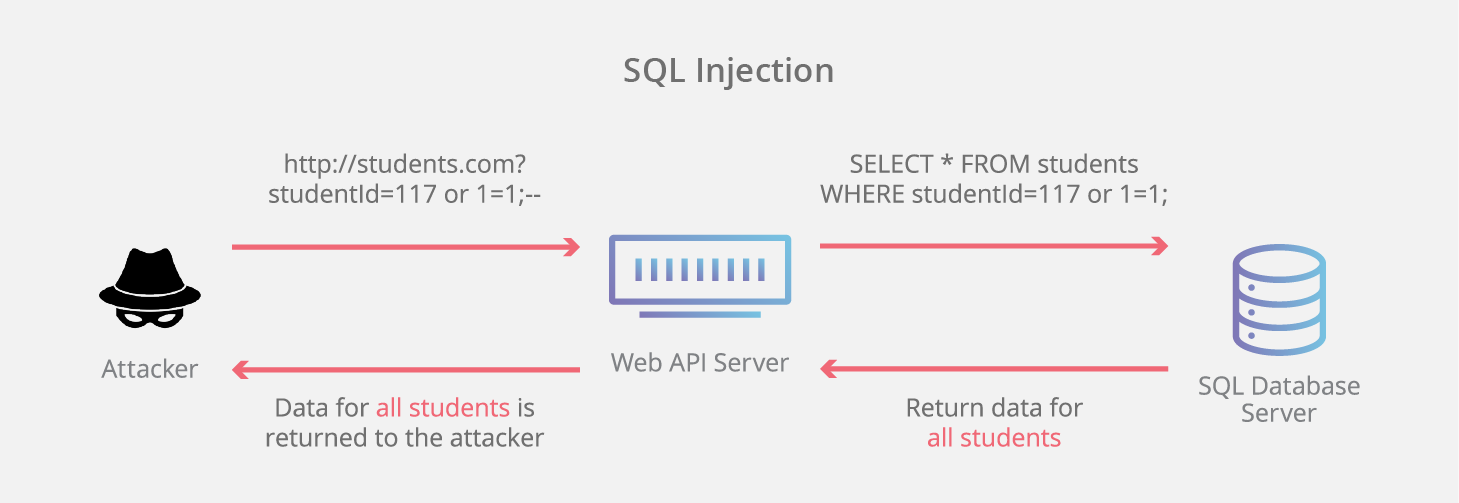
To address these security concerns, using small language models as guardrails can be more effective than traditional evaluations. These models can be specifically trained to:
- Detect and filter out potentially malicious prompts
- Validate and sanitize generated SQL queries
- Enforce access controls and data privacy policies
Implementing these smaller, specialized models as a security layer provides real-time protection, which is critical given the potential severity of security breaches in data access scenarios. While evaluations are useful for monitoring and improving system performance, the immediate safeguarding offered by these guardrail models is essential for maintaining the integrity and security of your data infrastructure.
© lytix