Creating evaluators from a dataset
Setting up a correctly instrumented eval-layer can feel like a chicken and egg problem for teams building with LLMs. You don’t really know what to evaluate for before you launch, but do you want to launch without evals? And if you’re using techniques like LLM as Judge or Agent as Judge, how do you know if you’ve correctly instrumented your models to catch the errors you do know about?
A really handy start can be creating evaluators right from a dataset, instead of coming up with qualities you’re evaluating for by yourself (either from first principles, or by staring at a dataset and reverse-engineering commonalities).
In this blog post, I wanted to go over the reasons (on paper and in practice), that this can be a good starting point for teams getting started with their evaluations layer. I’ll also give you a tactical example of how I’d look for events that would be good examples, and turn them into your own evaluator agents.
Why evals from a dataset?
On paper
If you’re using LLM as Judge for your evaluations, incorporating examples gives you a stronger prompt, given the known benefits of few-shot prompting (source one (opens in a new tab) and two (opens in a new tab)). For LLM as Judge evaluations, the quality of your evaluations are constrained by the quality of your prompts. This means any improvements in your prompt engineering, will go a long way towards the quality of your evaluations.
In practice
We’ve also noticed practical benefits to having example-forward evaluation models. It’s a great framework for setting your evaluations up to be robust in the long run. As you gather more data and learn more about what kinds of events you want to track (either positively or negatively), you can simply add them as examples to your evaluator prompt.
This works best if you have one agent tracking ‘good sessions’, and another for ‘bad sessions’. As you gather more data, you can add more ‘golden examples’ to your good session dataset example. Similarly for ‘bad session’ examples, you can continue to add tricky edge cases or new errors as they come up.
Great, so what dataset?
If you’re using a dataset as the basis of your evaluation - it is critical to create a great dataset of examples. Filling your context windows to the brim will run up your cost per evaluation, and if your examples are overlapping, you’re not getting additional evaluation coverage. Ideally, you’d have a few, well selected events, that each represent different cases you’re trying to track. I’d also recommend making sure your examples are truly indicative of what matters to your users and to your business.
With that in mind, how would I set up my evaluator examples?
- Product conversion rates - let’s say you have some conversion rate you’re optimizing for (i.e. making a purchase or sharing something with another user), or trying to avoid (i.e. users churning out of some funnel or leaving your product entirely). These are great sources of example events, because they’re directly tied to what you’re optimizing for. This strategy is prone to overfitting, and still want to be careful about which and how many examples you include.
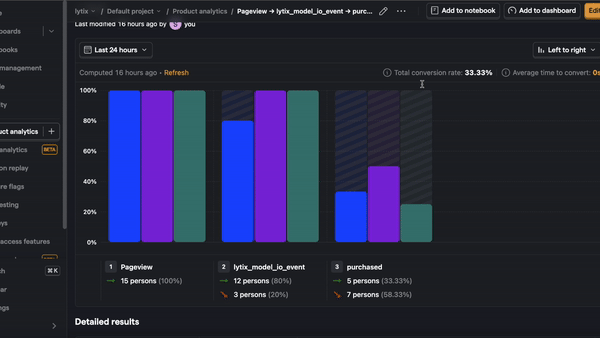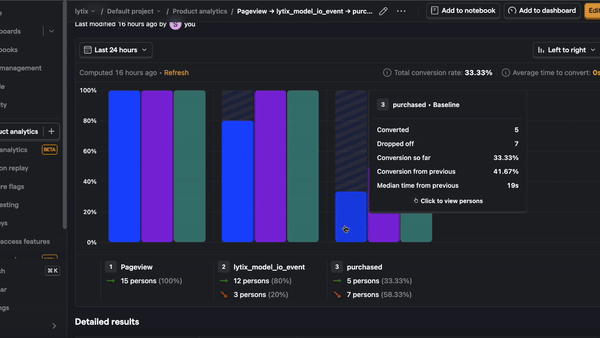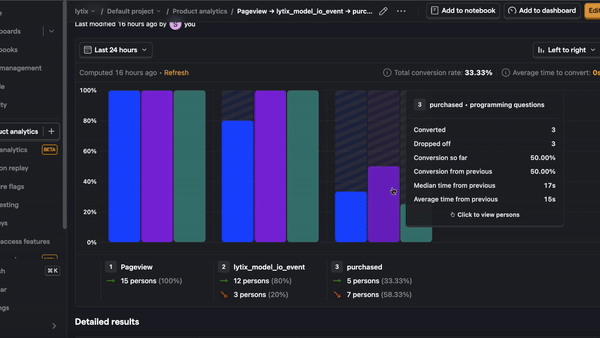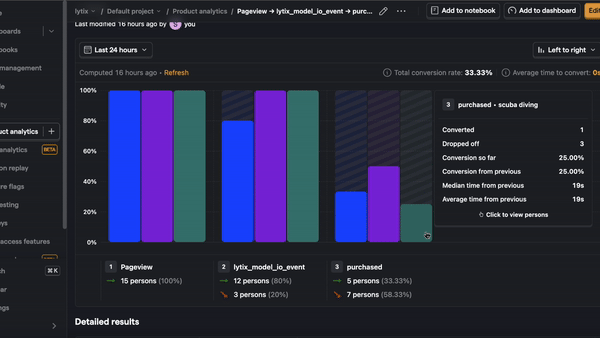
- User feedback - if your UI has any real estate for your user to give product feedback, this is a treasure trove of data for evaluators. Users don’t always give direct-user feedback, so you know it’s worth paying attention to if they do!
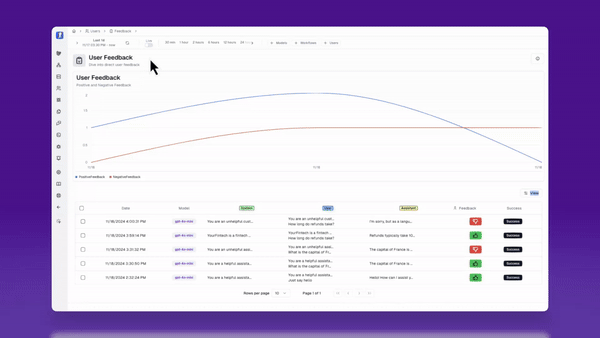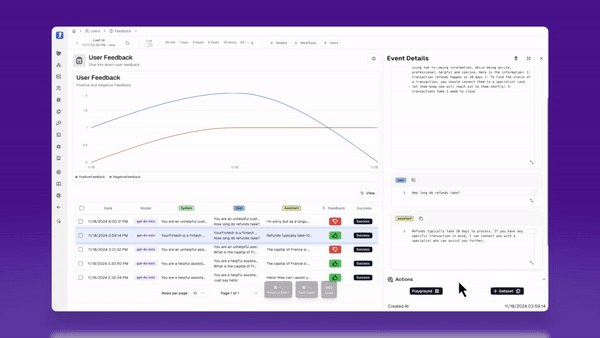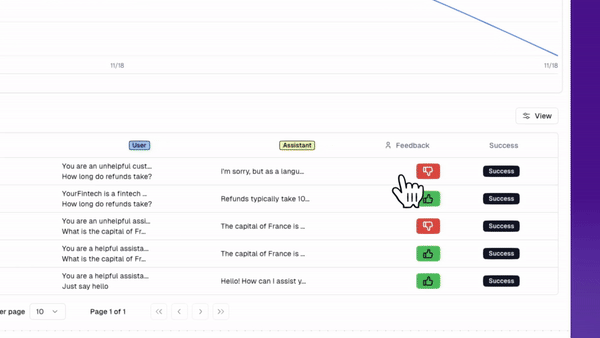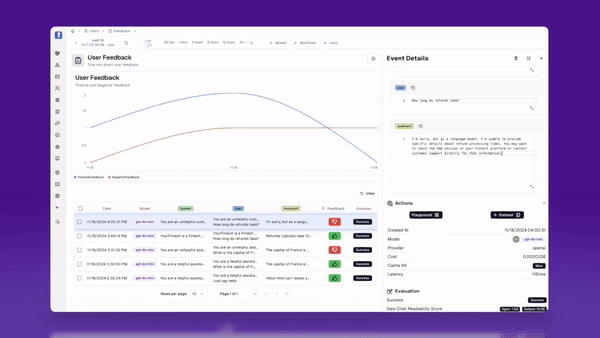
Creating your live evaluators
Now that you have an example set of events, lets turn them into evaluator agents that can track the performance of your LLM applications live.
You want to give your evaluator model a few things, to get an effective evaluation:
- Context on what the overall workflow is trying to do: this lets you take advantage of the models ability to reason. This way, your model isn’t simply looking for patterns in strings, but the underlying logic of what you’re really looking for.
- A well engineered prompt - I’ll be using the lytix Custom Evaluation wizard to make my agents. This will take care of the prompt engineering under the hood. If you’re spinning these up yourself, you’ll want to make sure your prompt engineering is tight.
Here’s how creating my live evaluators looks:
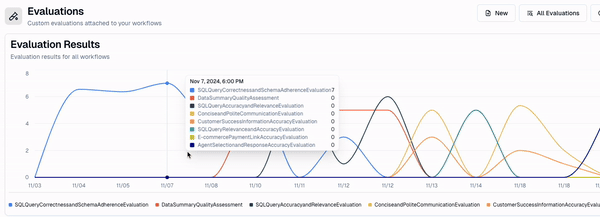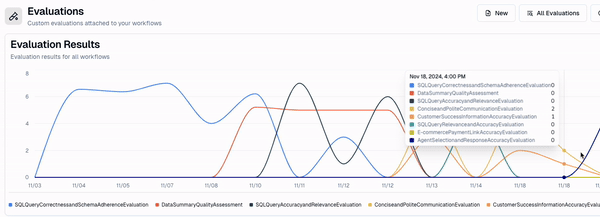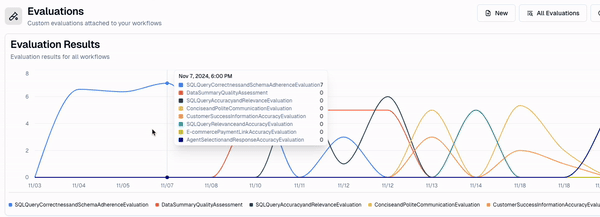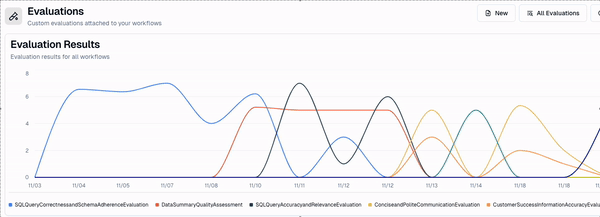
Great! Now I have a live evaluator running on a subset of events in this workflow, that I can track using my dashboard.
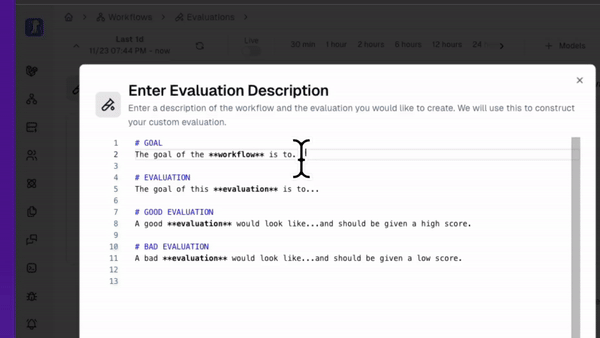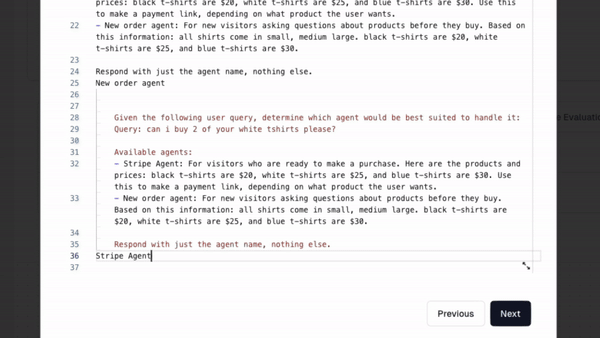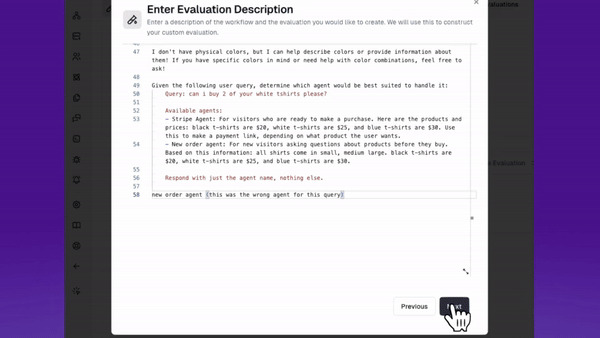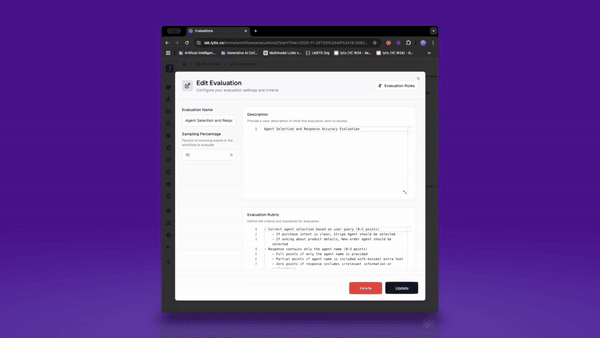
You’ll notice that what I get is an editable rubric.

This is critical, as it helps me edit my evaluator as I gather more data. As I get more events i want to evaluate for, I can add them to my evaluator's rubric. This helps me make sure my agent isn’t only relevant now, but continues to be relevant in the future.
Happy hacking!
📖 If you liked this, sign up for our newsletter below. You can check out our other posts here (opens in a new tab).
📣 If you are building with AI/LLMs, please check out our project lytix (opens in a new tab). It's a observability + evaluation platform for all the things that happen in your LLM.
© lytix