Computer Vision + LLMs = AI powered personal trainer?

I wanted to explore what I could build combining computer vision and LLMs. The majority of LLM’s use cases we come across were chat bots, search agents or summarization tools - I thought it would be fun to try something different.
I had a nagging side project on my list that seemed like a good fit - a bot that would look at your lifting technique and tell you if you were using good form or not. When I was new to the gym, I was worried about lifting with poor form (getting injured, learning bad habits etc…). In theory, one shouldn’t need to hire a coach for this kind of basic advice. Ideally, I’d like something that lets me hit the gym by myself, on my own schedule and is free. But still lets me know if I’m doing something wrong.
To keep things narrow, I defined my MVP as the following:
- A single lift - overhead press (correct form felt relatively easy to describe)
- The bot should be able to look at a single rep, and say if it was good form or not. (Giving advice or suggestions are out of scope for now - although interesting to explore for future iterations!)
Making computers see
First, I had to see what I had to work with in terms of computer vision models. I came across the Posenet Tensorflow project, which gives realtime coordinates of key body parts as you move through the webcam. This felt like a promising start - although I wasn’t yet sure how to use those estimations to check lifting form.
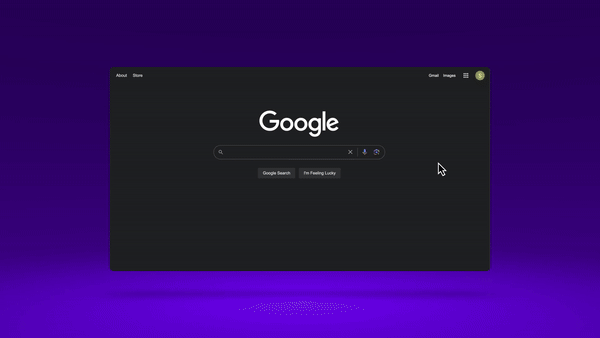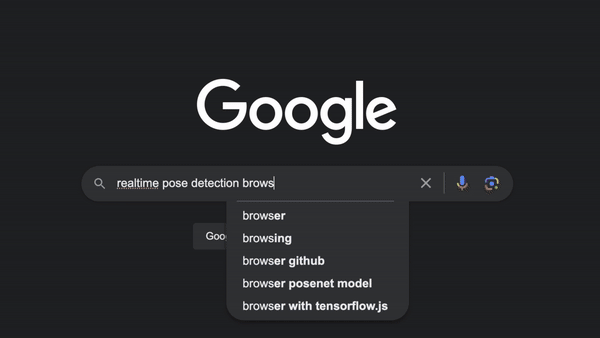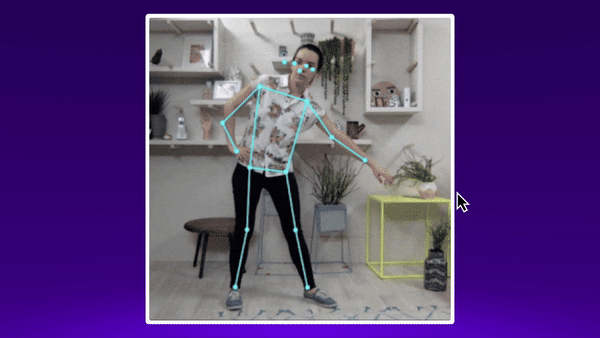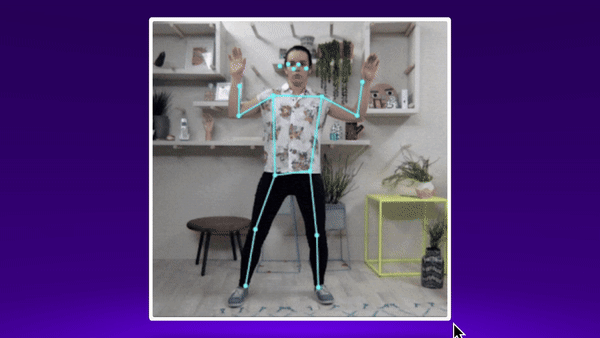
I used this (opens in a new tab) tutorial to bring Posenet into a React js web app, and start detecting poses in realtime.
While playing around with this code, I found the function that actually generates the pose estimations at some interval, as the user moves through the frame -
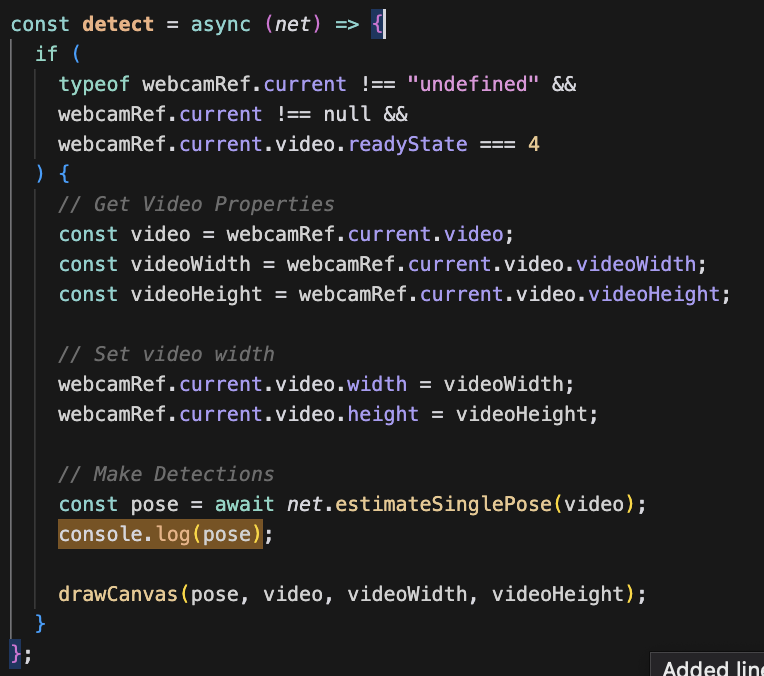
To figure out how I could work with these estimations, I first printed each estimation to the console, just to get a sense of what I was looking at. I saw that posenet estimations take the following shape:
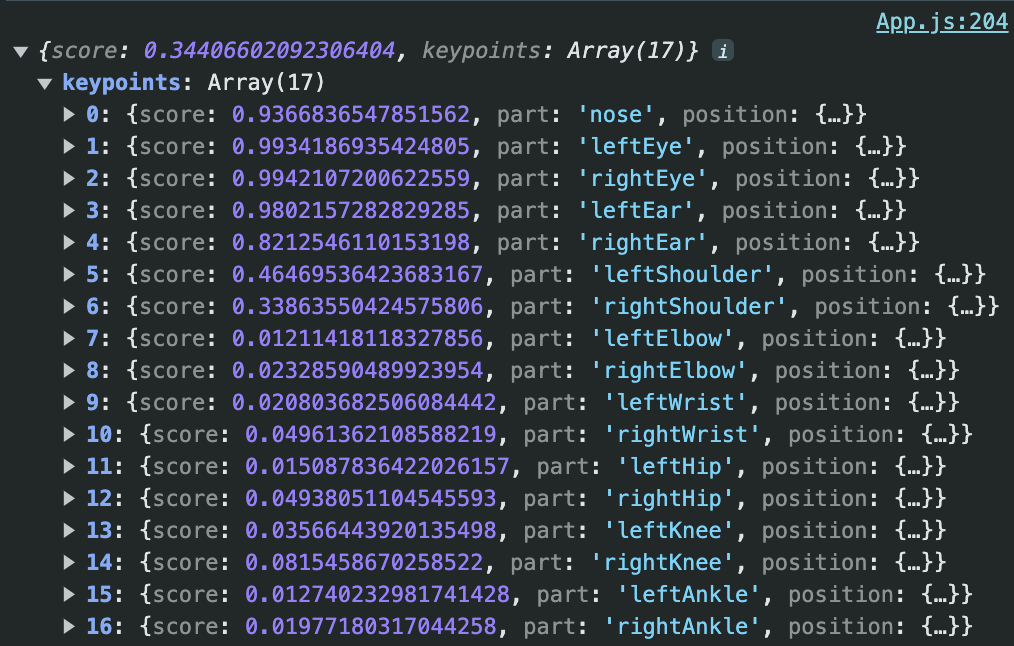
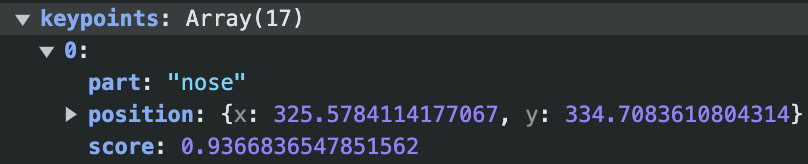
Each body part gets an x and y value representing it’s position on the canvas, and an associated confidence score. And I get a new set of coordinates for each body part, for each posenet estimation as the user moves through the frame.
Creating Coach LLaMa 🧢🦙
Next, I had to figure out how to use these coordinates to evaluate someone’s form. At first, I thought of downloading thousands of “good lifts”, have posenet extract patterns, and use that model to evaluate form. While that’s probably the smarter approach, I didn’t want to sink all that time into training a model so early in the project. So I tried a scrappier approach to start with-
- When the user “starts recording”, save all the coordinates of relevant body parts to a list, and convert that to a string. (Stop adding new coordinates when the user ‘stops recording’)
- Pass those coordinates to an LLM, with some context on what “good form” looks like. And used a few prompt-engineering tips to increase my chance of good results 😉
I also added a bit of logic to support different prompts for different lifts in the future
Prompting Coach LLaMa -
Figuring out the right prompt took a while here.

I started with just setting some context about the list of coordinates, and how they should analyze them (and some cheeky prompt engineering at the end to increase my odds of a good result.)
Good news ✅:
- The approach of passing coordinates as a string seems to work!
Bad news: ❌ These results were okay, but a little unnatural:
- It would often talk in terms of units - “your right wrist was 14 units from the elbow”. While I know what they mean, it wasn’t especially useful.
- Sometimes it would also grace me with all the calculations it made to produce that answer, also not helpful.
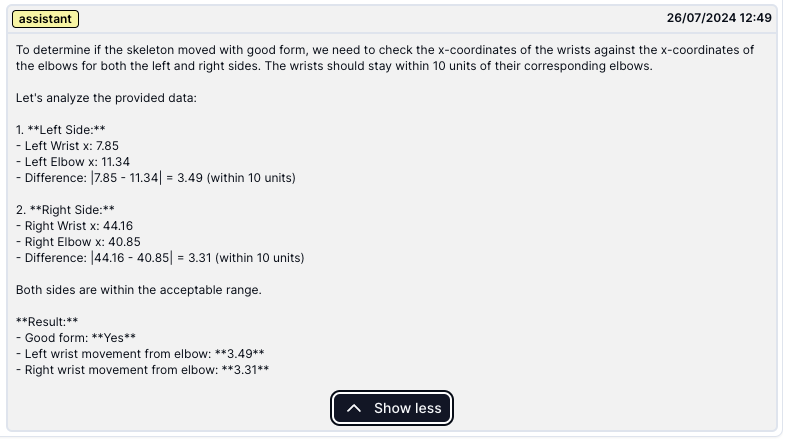
Then I tried asking it to be brief, and some prompt-tips to reduce it’s inclination to fill responses with words (i.e. tokens). I also used optimodel’s (opens in a new tab) maxGenLen parameter to force responses to be 20 characters or less, and gave it the role of “you’re a helpful coach”.

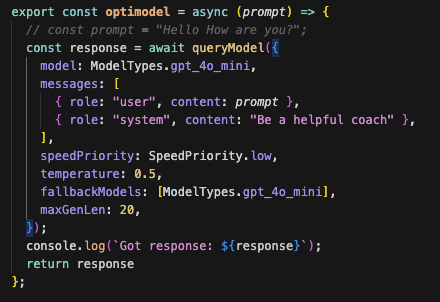
The result →
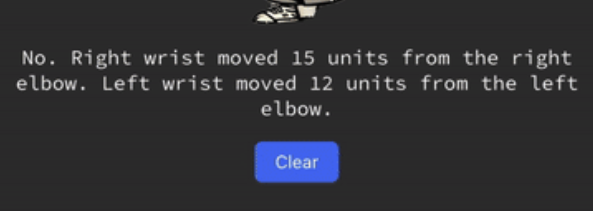
I stopped getting the math behind it’s analysis, and my responses were reliably concise. However, I was still getting my answer in ‘units’.
I wondered if this was because I incentivized shorter responses, and numbers let it be more concise. I adapted my prompt to give it more human-feeling context (”you’re a strength training coach giving advice on form”), and ended with “I don’t want to see any numbers”).

Great! No more numbers, and super quick responses.
 _(eventually I’d like to support follow up questions, but that felt out of scope for my MVP)._
_(eventually I’d like to support follow up questions, but that felt out of scope for my MVP)._
And we’re done! Let’s look at it in action →
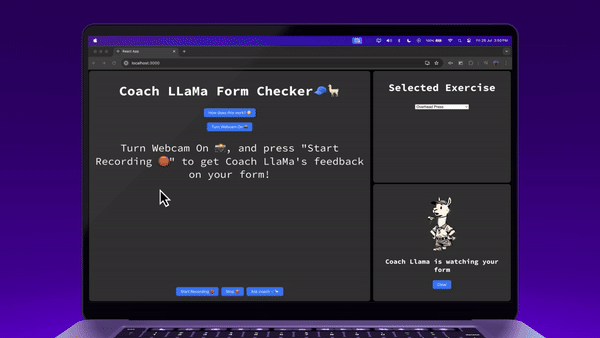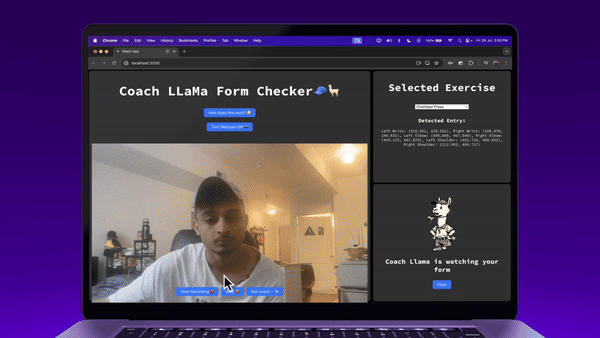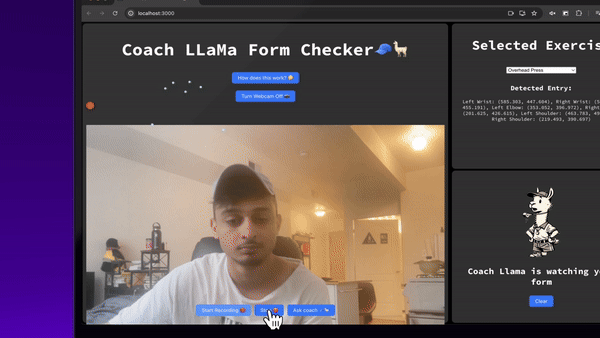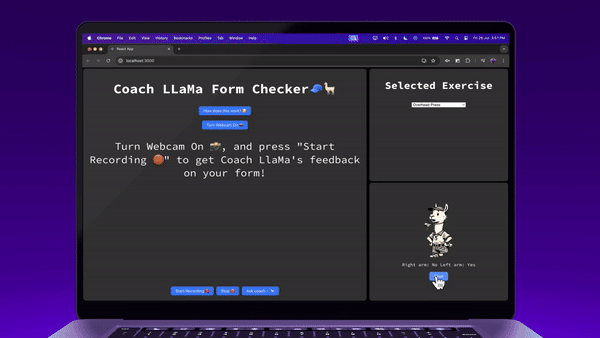
Try it for yourself at https://coach-llama.lytix.co/ (opens in a new tab)
Thoughts + What’s next:
- I was impressed with how far prompt engineering was able to get me. It took a bit of trial and error to find a prompt that would work reliably, but once I did I was happy with the results.
- For future iterations, I would formalize my prompt to be more of a “few shot + chain of thought” prompt. I’d give it an example of how I’d like form to be evaluated, along with some more specific instructions for “good form”.
- I’d also consider using a smaller/cheaper LLM, as I’m not sure I need something as big as GPT3.5 for this kind of evaluation.
- The posenet model itself was easy to work with, especially when it came to passing coordinates to my LLM.
- However, I did feel like it slowed down my webpage a lot. I’d consider exploring different pose estimation models that are also easy to work with, but enable a better user experience.
- I’d also like to think about more complex movements, such as bench or squat. These lifts have multiple criteria that need to be met before calling it “good form”. I’d be interested to see what the best way to handle those more complex cases would be.
- Should we have a different model evaluating each part of these complex lifts? I.e. one looking at the back position, one at the knee/ankle joint specifically etc… Or will one model be able to reliably check all criteria?
Check out the source code on Github here (opens in a new tab) 🚀
👨💻
📣 If you are building with AI/LLMs, please check out our project lytix (opens in a new tab). It's a observability + evaluation platform for all the things that happen in your LLM.
📖 If you liked this, sign up for our newsletter below. You can check out our other posts here (opens in a new tab).