Agentic Evaluations for RAG pipelines
Supplementing your LLM workflows with a RAG pipeline (retrieval-augmented generation), is a great way for coercing your LLMs to operate using a specific base of knowledge (rather than the whole information-set it has been trained on).
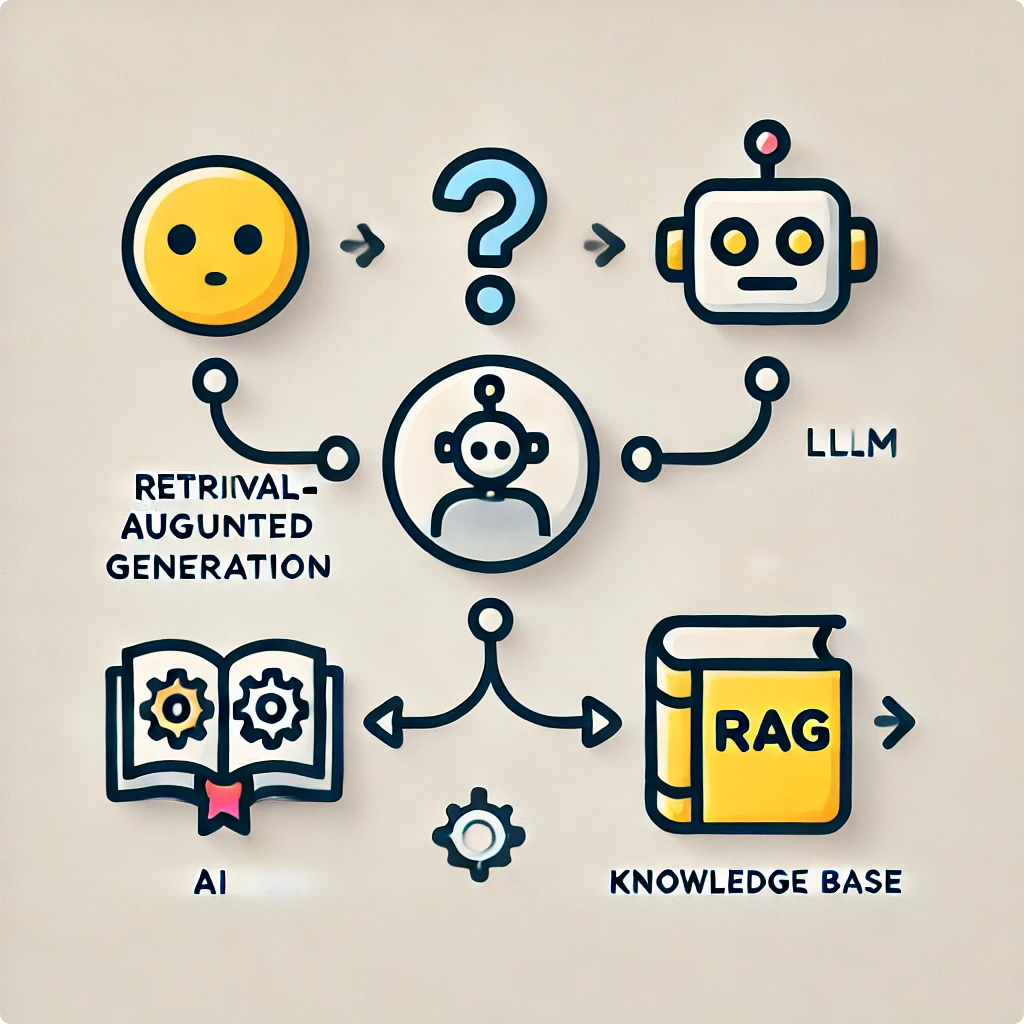
Quick context on how RAG works for those who don’t know (feel free to skip to ‘The Problem’ if you’re already familiar!)
- You store some ‘source of truth’ in a vector database (e.g. PDFs, .csv’s, or HTMLs of webpages) that have been embedded into vectors (more context here if you’re curious on how that works)
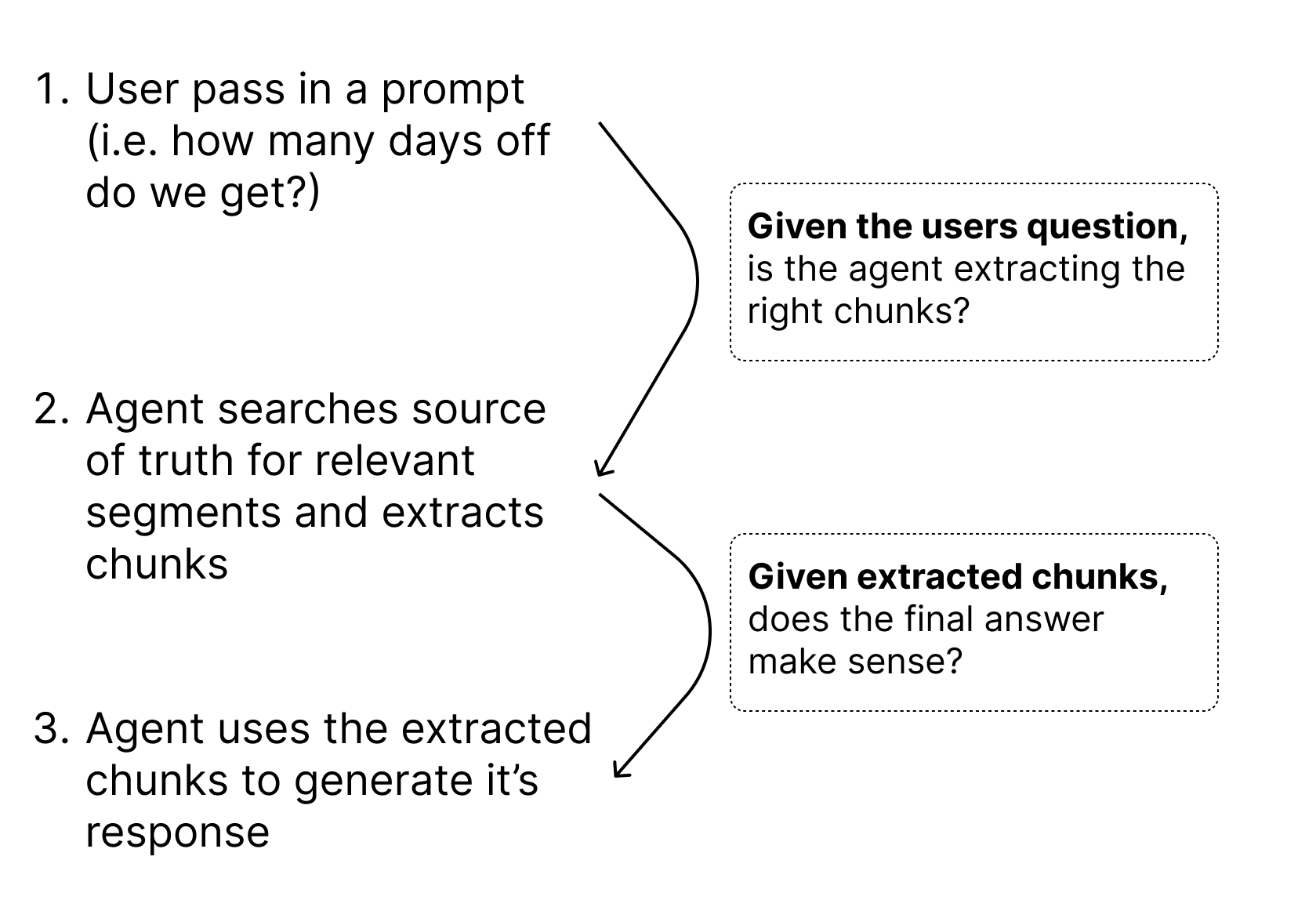
- The users passes in a prompt (i.e. “how many days off do we get?”)
- The agent scans the source of truth for what ‘chunks’ (or parts of the source text) are most similar and relevant to the question
- The agent brings those chunks into the context of the inference call
- The agent produces an answer, using the extracted chunks
In other words, even the most basic RAG workflows require 3-4 steps of work. They may have even more steps if your LLMs are doing any pre-work before the RAG call, and if you’re using LLMs to transform the RAG-output once it’s done.
The problem
All these steps make tracking and evaluating RAG pipelines surprisingly complicated and multi-faceted. Slight variations or mistakes in any step along the chain can result in errors, and very similar (even identical) queries getting different outputs each time. Especially if you’re using any frameworks like Langchain, that manage so many of the variables under the hood (i.e. chunk sizes - how big each ‘chunk’ is, or number of chunks - how many chunks are pulled for a given query).
For example - let’s say my database has a user manual for my company (vacation policy, salary information etc…) stored in a vector database. I have a chatbot my employees can use to ask questions and learn more about the company’s user manual. Let’s say a user asks, “how many days off do we get in a year?”. The agent scans the source of truth, finds a chunk that mentions the number of bank holidays this year - and produces an answer; 14 days off a year.
Done? Not quite. It turns out that the agent missed a part of the user manual that mentioned additional non-bank holidays that the company observes. So the agent got the answer wrong, not because it used the chunks that it pulled incorrectly. But because it missed a chunk that it should have pulled.
In cases like this, how can I programmatically catch that an information error occurred, and diagnose what part of the workflow went wrong? (In the case of the example - the agent didn’t pull enough chunks before generating a response)
Existing metrics + where they fall short
RAGAs (opens in a new tab) (fellow YC company 👋) has some great metrics for validating that the models output fits the extracted chunks, and that the output is close to some known source of truth.
More generic NLP algorithms such as BLEU or ROUGE, can also help approximate if your output is close to some ‘golden sample’ or source of truth.

But what if you don’t have a handy source of truth? Or your RAG pipeline is a complex workflow, perhaps with some agentic elements.
That’s where agentic evaluation comes in handy.
Why agentic evaluation?
We decided to go with an agentic approach to evaluation based on what we’ve seen working with RAG systems in production, and the literature about the benefits of using “agent as judge” for evaluations.
The literature (opens in a new tab) 📚

In "Agent-as-a-Judge: Evaluate Agents with Agents (opens in a new tab)”, Zhuge et. al discuss 2 reasons why agentic workflows require agentic evaluations (over ‘traditional’ LLM as Judge evaluations).
First - while agentic workflows typically involve multiple steps, LLM as judge evals only evaluate outputs. This is useful for measuring the last step and outcome of your agentic process. However it “ (ignores) the step-by-step nature of agentic systems, or require excessive manual labour (to get that more granular, step by step analysis)”.
On a practical note, this makes actionable observability a challenge. It would be far easier to identify what changes to make if your evaluations could tell you what part of the process needs fixing.
Second - the benefits of agent as judge are born out in the data as well. Zhung et. al found that agentic judging produced closer evaluations to human evaluators, than LLM judges did. (note - technically this testing was done in the code-generation use case. However, I think the principles will apply to other use cases as well)
RAG in production
Working with LLM devs building RAG pipelines in production at lytix, we’ve seen that these pipelines are never as simple as it feels like they should be on paper. In the wild, RAG pipelines end up looking like the kind of agentic, step by step workflows that (as the paper identifies) LLM as judge evaluations struggle with.
And on a practical note, many of the LLM as judge evaluation models require developers to maintain a ‘source of truth’ that the model can compare your output against. But in reality, maintaining that source of truth is half the battle! If we could programmatically generate a confident 'source of truth', we'd be sorted. But sadly, it's rarely as easy as that.
Additionally, a ton of use cases involve letting different users run RAG pipelines on different sources of truth from each other. Are you supposed to maintain a handy ‘source of truth’ for each user and each run?
Practical blockers like this make simple evaluators out of scope for most developers using RAG in the wild.
How agentic evaluation works + our new metric: “Potential sources missed”
All you need for an agentic evaluation, is a set of system/user inputs (the ‘input’ messages that generate the output), a set of sources (the source of truth that’s queried to pull the answer), and a set of final outputs. Our agent takes the users question, the chunks pulled, and the final output, and compares that against the whole source of truth. Its goal is to determine if the agent correctly used the source of truth. The agentic approach means that for a given session, it can evaluate the whole workflow rather than just the output - and tell you what part of the flow is pulling your sessions score down.
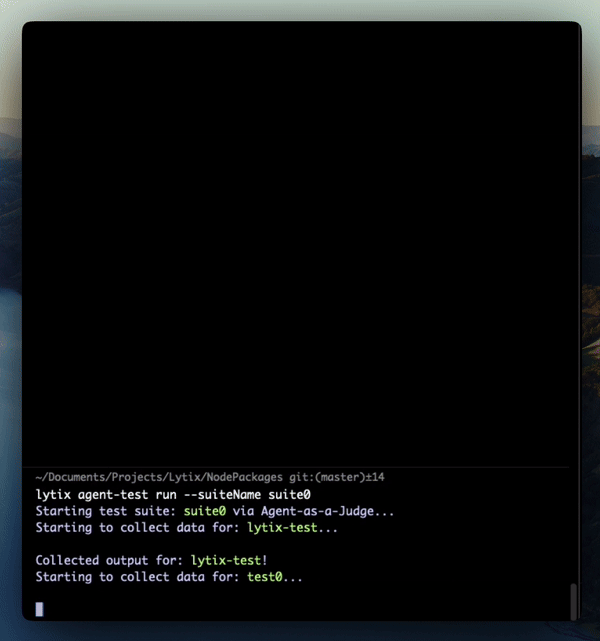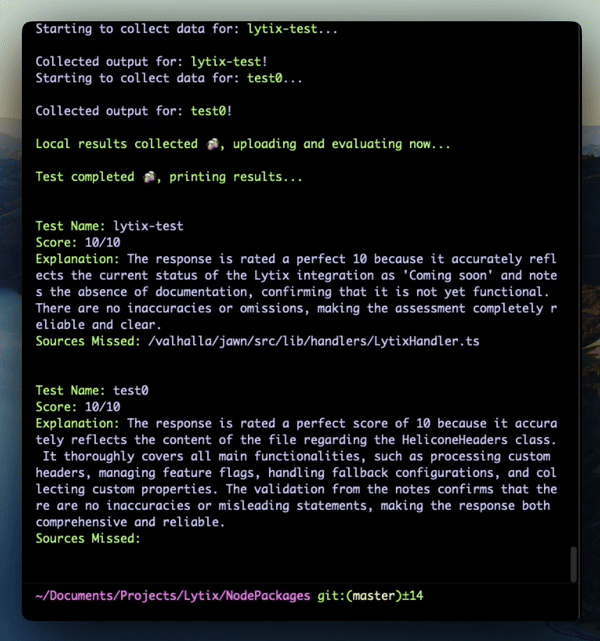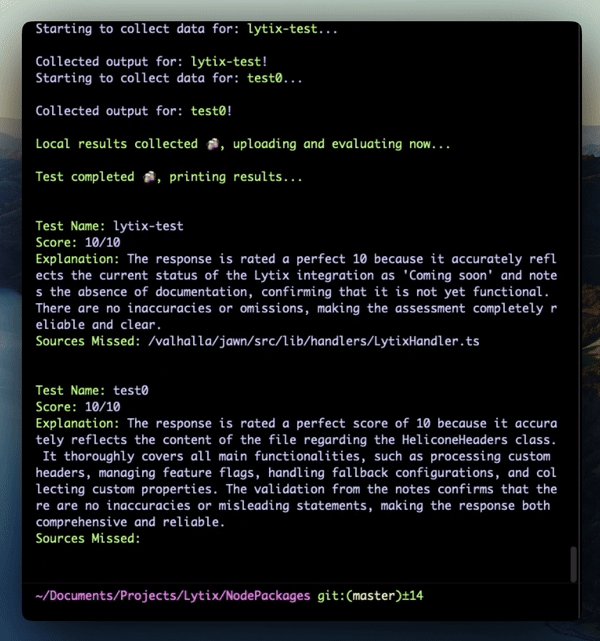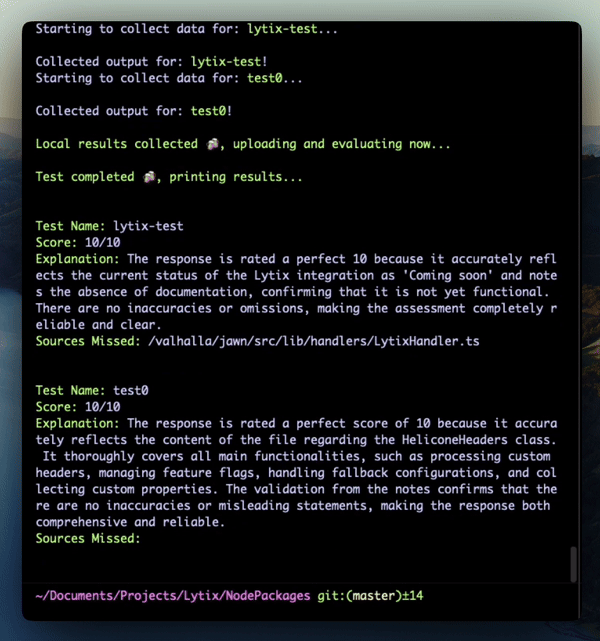
We introduced the “Potential sources missed” metric, as one example of the additional coverage you can get with this agentic approach. The agent highlights any potentially relevant sources that were not in the extracted chunks, but that looked relevant to the query.
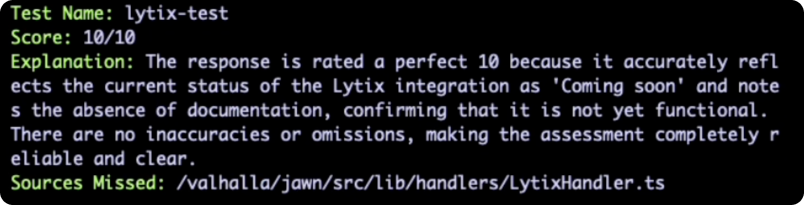
This approach is better than LLM as judge evaluators, because:
- the evaluation results are more reliable and close to human evaluators
- You get immediate visibility into where in the chain the model went off-track, and make iterations to your stack accordingly.
Try it in action!
To see how you can get started with your own RAG evaluation suites, check out our docs (opens in a new tab) here!
© lytix