Google, OpenAI, and the Open Source Problem

From Google:
We have no moat. And neither does OpenAI
That’s what an anonymous researcher claimed in an internal memo (opens in a new tab) that was leaked to the public in May 2023. But according to the same memo, OpenAI isn’t even Google’s main concern.
The memo points to several critical AI challenges the open source community has cracked well before private companies have. Some are technical challenges, such as multimodality (opens in a new tab), or creating entirely personalised AIs. But some are distribution problems, such as making models small enough to be run locally on smartphones. All solved in open source first, before private companies could catch up.
But this feels wrong - how could a community of uncoordinated hobbyists outperform the biggest tech companies of our time?
The memo points argues the following -
1. Diminishing returns from creating foundational models from scratch
From late 2022 till today, we saw an explosion in the number of large foundational models. GPT 3.5, (and its family of peer models; Llama3, Gemini 2 etc…) were huge improvements over what came before, and were in some ways the first true large language models. These improvements were driven by making models bigger; more parameters, larger datasets, trained for longer and given more compute.
This is not only the hardest part of the process, but is becoming less impactful.
Creating larger and larger base models is challenging because of the enormous amounts of compute, data (and therefore capital) required. This made creating base large models out of scope for the open source community, and only applicable for large companies. While this was true, improving AI was up to the Big Tech companies who had the resources to create bigger foundational models.
However, it’s no longer clear that models get better as they get bigger. Speed, task completion, reasoning ability, modality etc… don’t automatically improve for every task as models get larger. (This has actually known for a while - here's (opens in a new tab) OpenAI’s CEO Sam Altman saying the next breakthrough in AI will have to come from something other than LLMs.)
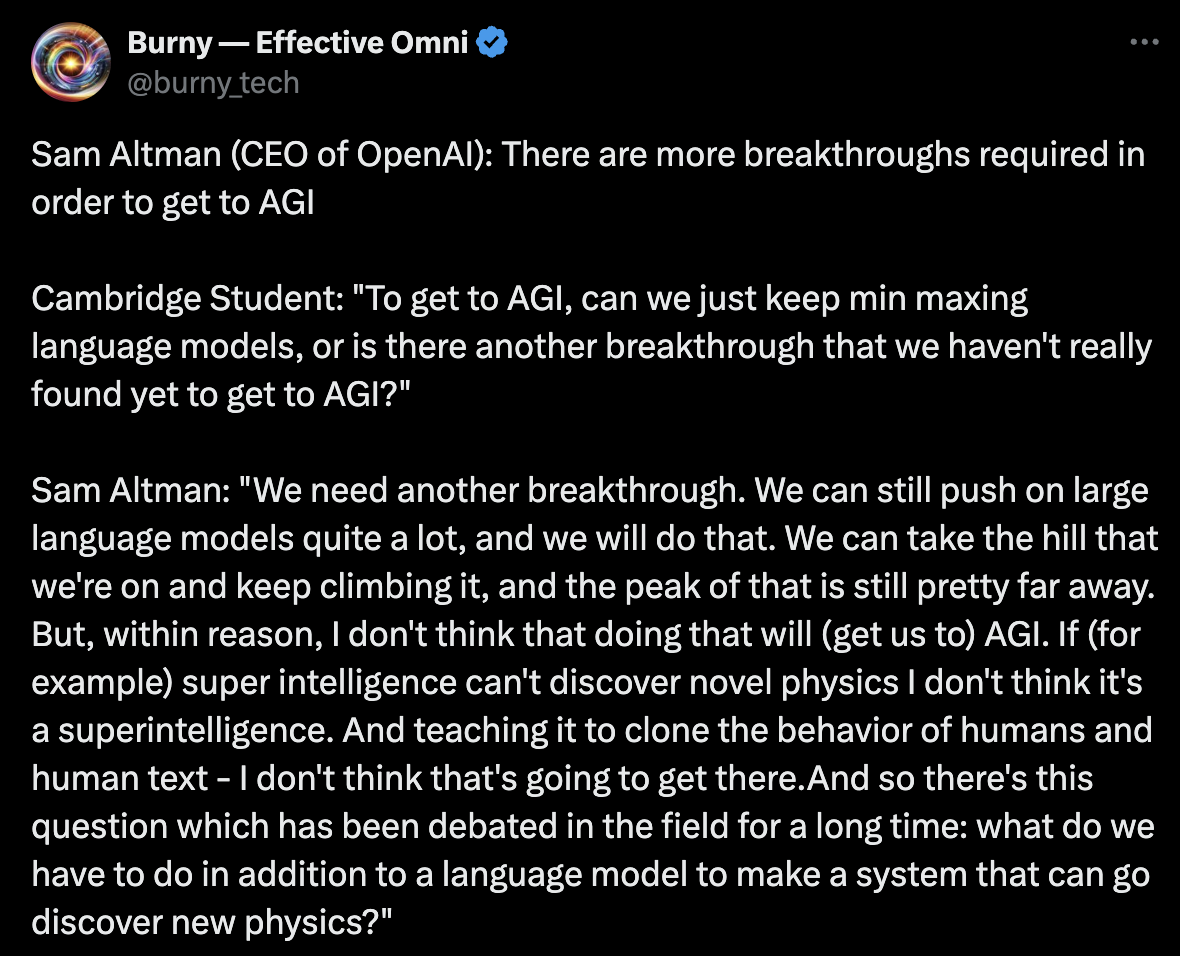
In short - what only big tech companies could do (create large models) is no longer the only, or even best way to make AI better.
So how are models getting better? Answer - finetuned, smaller models. And this has brought open source into the AI ecosystem in a profound way
2. Open-source discovers the power of finetuning
According to the memo, Google (and it’s peers) have thus far overlooked the power of finetuning. Finetuning base models has several advantages -
“Finetunes” can be stacked.
Finetuning techniques, like LoRA, work by taking a base foundational model, and adding ‘layers’ that further customize its behaviour. These ‘layers’ are datasets that show the model how it should change its behaviour. For example, one could give a base model specific domain knowledge by further training the model on a dataset of key-value pairs ({question: answer}) of the new domain. After retraining, your model will be particularly good at answering questions in that particular domain.

What makes this particularly effective is the ability to stack layers, and quickly iterate to give a base model several new behaviours. The memo writes;
Improvements like instruction tuning can be applied and then (…) other contributors add on dialogue, or reasoning, or tool use. While the individual fine tunings are low rank, their sum need not be, allowing full-rank updates to the model to accumulate over time
In other words - several finetunes of a base model can achieve the same results as training a new model from scratch!
Access to compute and creative solutions to the data problem, have made finetuning widely accessible.
What makes this observation particularly powerful is how accessible finetuning is. Hobbyists can rent a GPU for ~$100 and finetune a model in a day. Within a week, a hobbyist could stack finetunes and almost entirely retrain a base model for less than a thousand dollars.
The open source community has also solved the data problem, and figured out ways to get around the need for huge amounts of data. Smaller, but highly curated datasets can be just as effective (if not more) than large amounts of data. Hobbyists have also found ways to use synthetic data, data generated by other LLMs, to further customize model behaviour.
So where does Google go from here?
If competing on model performance is a moot point, what should Google be doing next? The memo reveals a few interesting hints at Google's potential next steps:
1. Working with, vs competing against open source
(We) can’t compete with open source…We need them more than they need us
The memo argues that open source models are becoming hard to deny. As the performance gap closes, why should developers use paid ,private models when free alternatives are just as good, if not better?
Open source has proved effective at solving technical challenges faster than private companies. And as researchers move freely between AI companies and free research hubs make research more affordable, LLM “know how” has become commoditized. Insights that may be a competitive advantage now, are unlikely to be durable moats for anyone building privately.
We can try to hold tightly to our secrets while outside innovation dilutes their value, or we can try to learn from each other.
2. Owning the ecosystem
At least in the short term, Google sees a world of many models. Some large general purpose, some small and specific. Some developed open source, some by private companies.
Could this signal a change in strategy?
Rather than competing in the emerging model marketplace, could Google be shifting gears to holding a Play Store/Android/Chrome-like position? “Owning the platform where innovation happens”, vs. betting on the innovation itself. From the memo -
Google itself has successfully used this paradigm in its open source offerings, like Chrome and Android. By owning the platform where innovation happens, Google cements itself as a thought leader and direction-setter, earning the ability to shape the narrative on ideas that are larger than itself.

While we can’t index too heavily on a leaked memo from an anonymous researcher, the contents of memo does align with the learnings we’re hearing from elsewhere in the industry.
Meta has famously made open source a big part of its AI strategy, making its models available for free. Meta has also embraced a multi-model future; with Llama3 being especially easy to customize via open weights, and are themselves releasing specialized small language models (for ex. Llama Guard (opens in a new tab), a small langauge model specialized for detecting threats in human-bot conversations).
Apple’s recently released Apple Intelligence, also shares Google and Meta’s vision for a future with multiple models. Apple seems one step ahead of Google, already taking steps towards their “app store for AI” model (opens in a new tab); Apple Intelligence itself relies on some models that are developed in house, and some developed by 3rd parties (including OpenAI’s ChatGPT).
OpenAI, however, seems to have continued down its path of productizing its closed models, and hasn’t made nearly as much noise about open source. Is embracing open source in their future? Does OpenAI think about the open source problem differently? Or is OpenAI angling to become the “Apple” of AI - a closed, private platform that exists alongside the open platform?
👨💻
📣 If you are building with AI/LLMs, please check out our project lytix (opens in a new tab). It's a observability + evaluation platform for all the things that happen in your LLM.
📖 If you liked this, sign up for our newsletter below. You can check out our other posts here (opens in a new tab).